Model_Parallel
张量并行(TP)
对模型参数矩阵进行划分,划分为不同的张量,分发到不同gpu上进行计算,最后再进行汇总。这里与ZeRO-3的参数划分并不同。(ZeRO-3是将整个参数矩阵展成一维向量后进行平均划分,参数矩阵同一行的内容也可能被划分到不同gpu上。)
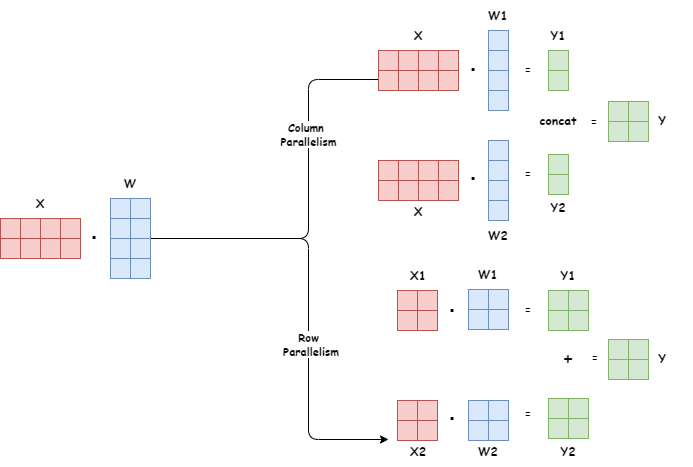
具体实现张量并行(Tensor Parallelism, TP)有两种思路: * Row Parallelism:
\[
XW = \begin{bmatrix}
X_{1} X_{2}
\end{bmatrix}
\begin{bmatrix}
W_{1}\\W_{2}
\end{bmatrix} = X_{1}W_{1}+X_{2}W_{2} = Y_{1}+Y_{2}=Y
\] * Column Parallelism: \[
XW = [X][W_{1} \ W_{2}] = [XW_{1} \ XW_{2}] = [Y_{1}\ Y_{2}] = Y
\] 
TP对带宽要求较高,不建议跨多个节点进行TP训练,机器之间的数据传输是比较慢的。
流水线并行(Pipeline Parallelism, PP)
传统PP
对于多层的模型,当参数过大,单卡装不下时,一个直观的方式就是按层切分,每一部分放到一块上。假设模型有L层,我们有K块GPU,简单起见假设\(L\%K=0\),那么就可以每\(\frac{L}{K}\)层的参数放到一个GPU上。 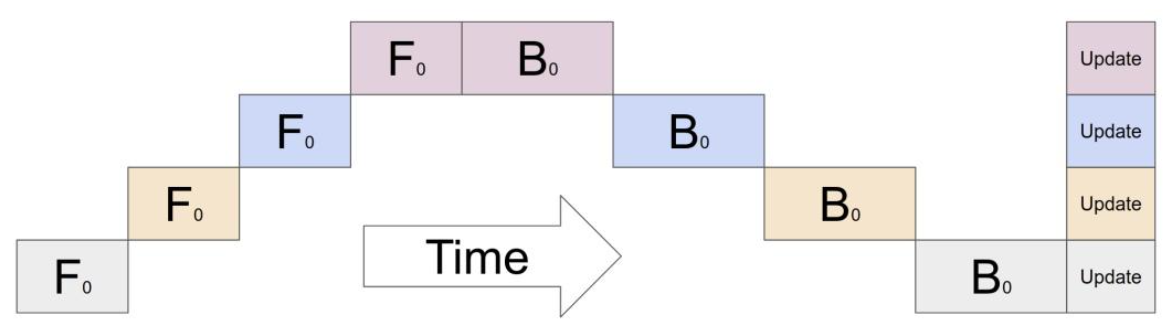
上图是具体的模型训练过程中不同gpu的运行负荷和时间。前向传播部分逐块进行,当前向进行到第一个gpu上时,其它gpu都是空闲的。反向传播过程类似,最后会有一块额外的时间消耗,每一块gpu根据反向传播计算得到梯度进行参数更新。 这个实现非常符合直觉,但是显然其对gpu的利用率是非常低的,gpu空泡率为\(O\left( \frac{K-1}{K} \right)\),gpu数量\(K\)越大,空泡率越接近1,即gpu资源基本都是被浪费的。
Gpipe
上述传统PP的问题主要在于,由于数据处理的串行特点,一个batch的数据在处理的时候,其它gpu没办法运行。Gpipe提出把一个batch的数据再重新拆分为多个Micro-batch,提高并行程度,那么就可以减少等待的空闲时间。 虽然我们可以通过将 Micro-batch 划分到最小来减少 Pipeline Bubble,但需要注意的是,让 GPU 执行一次 Batch_size=32 的计算和执行 32 次 Batch_size=1 的计算,二者的效率天差地别。所以在实际中需要综合考虑 Micro-batch_size 和 Pipeline Bubble 来进行权衡。
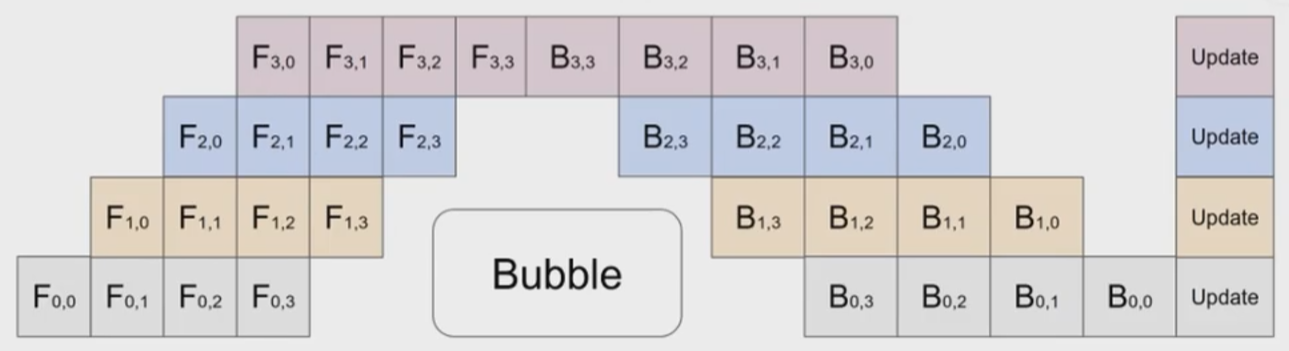
Gpipe本身是传统PP的一大优化,但是其依然是先前向处理完所有的数据,再进行反向传播。这意味每一层前向完之后,需要保存所有激活值(目前处理手段是引入gradient-checkpoint进行缓解),这是一笔很大的梯度开销。
### PipeDream
PipeDream在Gpipe基础上进行显存峰值的优化。其采用1F1B的数据处理策略。
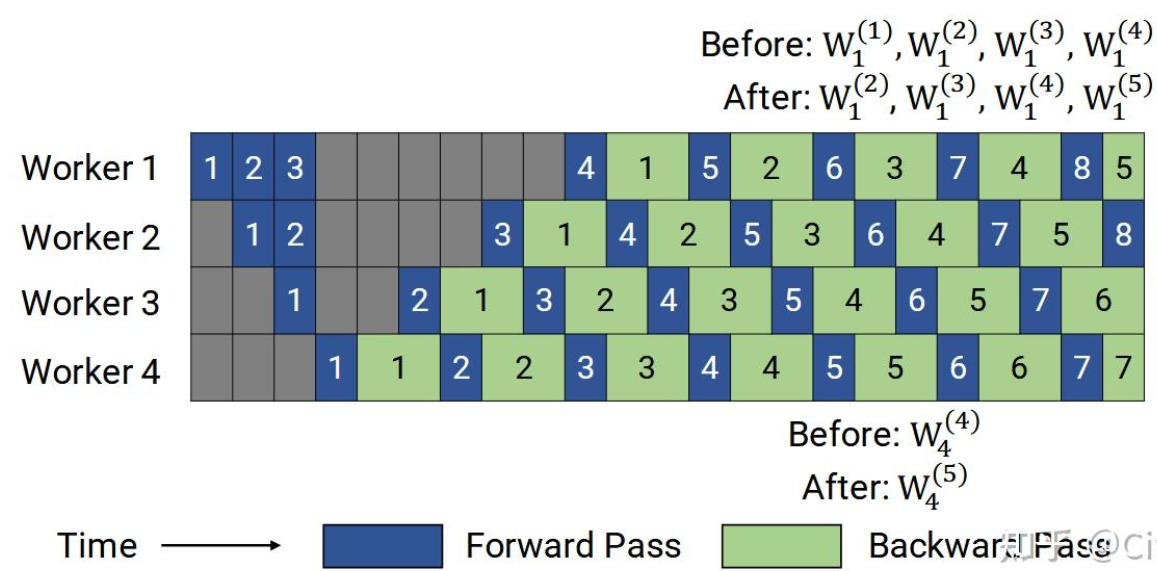
在gpu4处理完batch1的数据之后,就立马做其对应的反向传播,那么之后处理batch2数据的前向传播时,就可以完全丢弃batch1对应的所有激活值了,从而降低了显存峰值。假设单个Micro-batch的激活值显存为\(A\),那么Gpipe的显存峰值可以表示为\(O(M\times A)\),与Micro-batch的大小\(M\)有关,而pipeDream的显存峰值则接近\(O(A)\),这是巨大的显存优化。
原则就是“尽早执行反向计算”
就 Pipeline Bubble 占比而言,PipeDream 明显优于 GPipe,并且随着训练的进行,Pipeline Bubble 会越来越少。