Data_Parallel
含义很好理解,模型在不同gpu中直接是完整的副本,但是数据会划分为不同的batch分发进行训练,然后不同gpu将各自的梯度信息汇集再分发。 主要分为两个架构:PS-Worker以及Ring-AllReduce
PS-Worker
这是早期 TensorFlow、MXNet,torch.DP(已经弃用) 等框架广泛采用的方式。这里的PS是指Parameter Server PS有两种选择:CPU或者GPU
使用CPU的话,GPU与CPU之间只能通过PCIe进行数据传输,这个带宽相比GPU之间的NVLink来说是低很多的 [[PCIe VS NVLink|(参考这里)]],这是一点。 但是PS-Worker架构本身,哪怕使用GPU作为PS,主卡的负载也比其它GPU大很多,主卡的性能和通信开销很容易成为瓶颈。同时,主卡在计算时,其它gpu在发呆,gpu利用率也很低。
Ring-AllReduce
这是目前 NVIDIA、PyTorch DDP、Megatron-LM、DeepSpeed 默认采用的方法
相比于PS-Worker,它将数据聚合与计算的压力从一个PS分发到所有gpu上。这里每张卡只与其下一张卡进行数据传输操作。
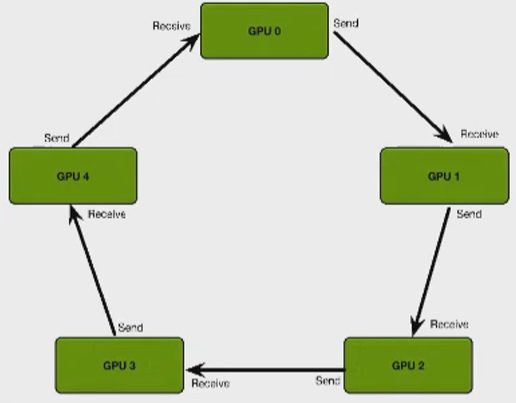 整个Ring-AllReduce包含两个过程:
整个Ring-AllReduce包含两个过程:
scatter-reduce以及allgather
scatter-reduce
将每一块GPU上的梯度信息分为N块,其中N是gpu数量。
那么目标是要将不同gpu上不同块的信息聚合(这里以加和操作为例)并进行分发。在实际操作中,会执行N-1次数据传输操作,每次将当前卡的对应block的数据信息传输到下一张卡上并进行聚合。以第一次操作为例,gpu0将\(a_{0}\)信息传给gpu1,gpu1将\(b_{1}\)信息传给gpu2,以此类推。第二次操作时,gpu1将\(a_{0}+a_{1}\)这个信息传给gpu2,... 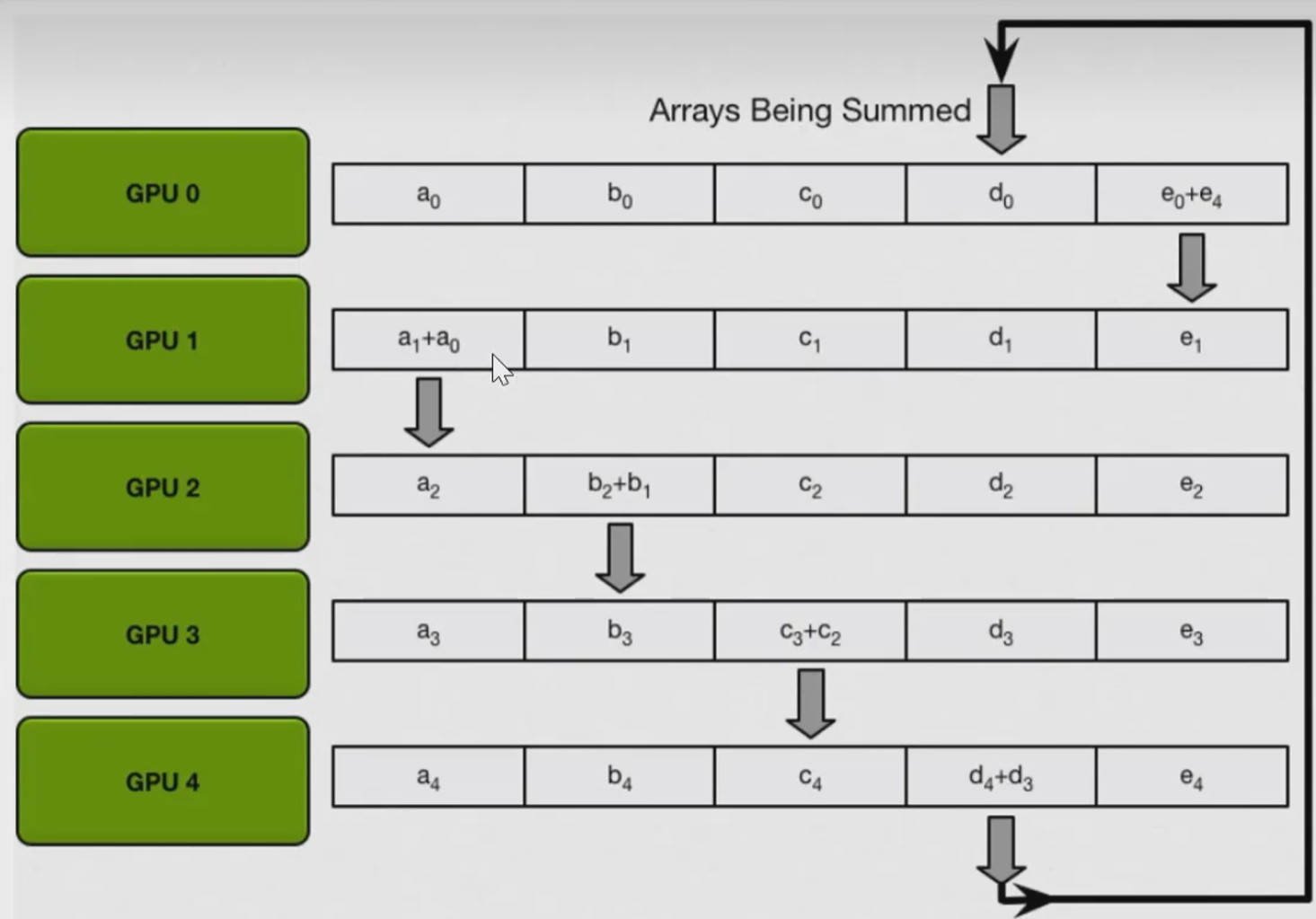
那么执行N-1次操作后,每一张gpu上恰好会有一个block是包含了所有gpu的完整数据信息的。接下来就是要把每一块的数据进行分发同步到其它gpu上。

allgather
allgather操作执行的过程与上一步类似,只不过由数据聚合变成了数据分发。同样需要执行N-1次。
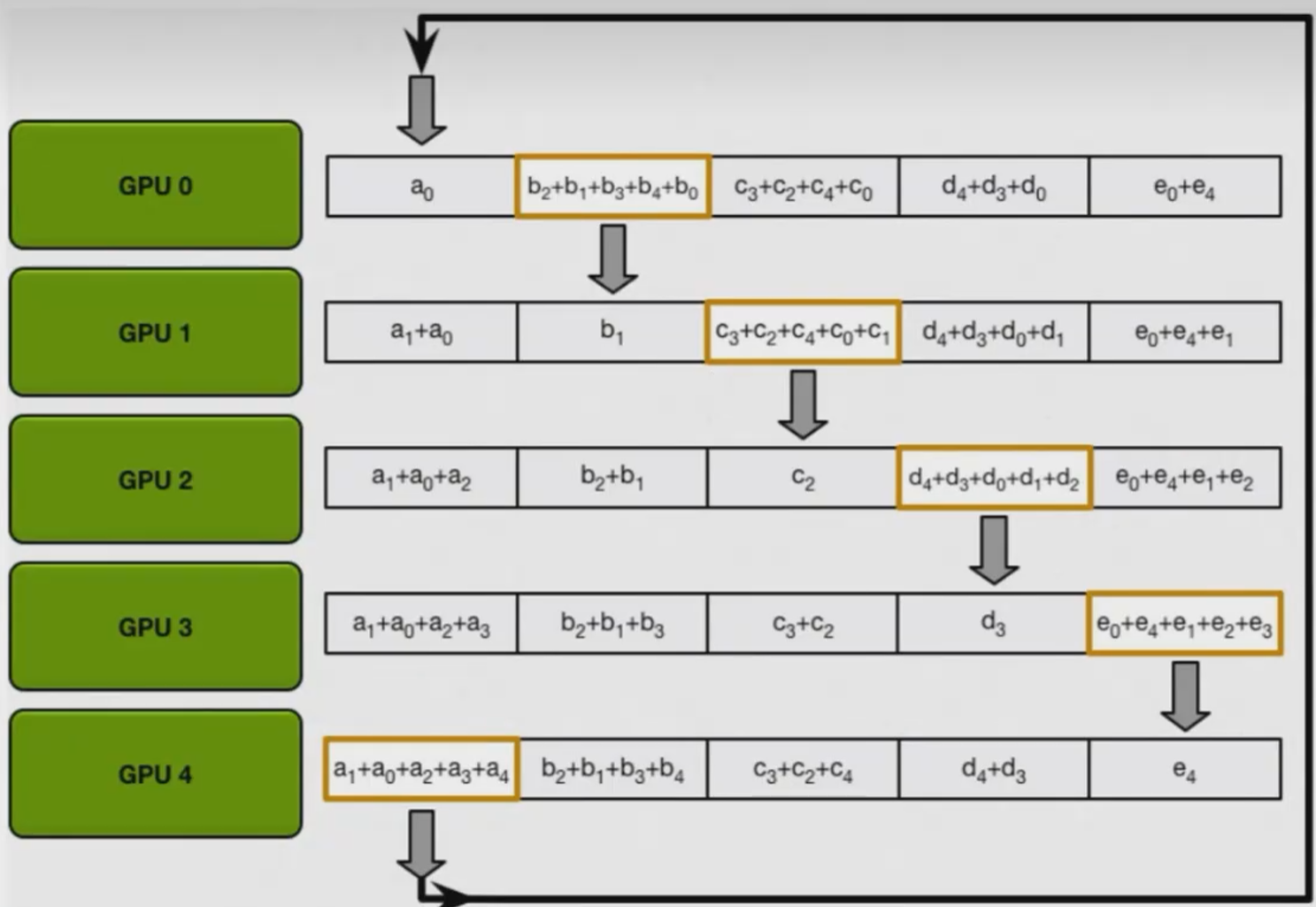 以第一次操作为例,gpu4将第一个block的信息同步给gpu1,其它gpu执行类似操作,把自己内部有效的完整信息部分进行分发。第二次操作时,再把上一轮收到的信息发给下一个gpu。N-1次操作后,所有gpu的每一个block都会包含完整信息。
以第一次操作为例,gpu4将第一个block的信息同步给gpu1,其它gpu执行类似操作,把自己内部有效的完整信息部分进行分发。第二次操作时,再把上一轮收到的信息发给下一个gpu。N-1次操作后,所有gpu的每一个block都会包含完整信息。
Torch.DDP的实现,就是通过Ring-AllReduce来进行每张卡上前向传播完之后梯度信息的聚合和更新,来保证每轮操作之前,每张卡上都是相同的更新好的参数。
- 通信量分析 设模型参数量为\(\Phi\)。两个阶段都要执行N-1次数据传输操作,每一次传输的数据量是\(\frac{\Phi}{N}\),那么总数据传输量是 \[ 2(N-1) \times \frac{\Phi}{N} = 2 \frac{N-1}{N} \Phi \] 其存在固定上限\(2\Phi\),即\(2\)倍模型参数量。因此gpu数量增加并不会带来通信成本的无限增长。 (这里分析的是单卡的通信成本,而不是总线带宽。)