ZeRO
模型训练时,gpu上需要存储的参数包括: 模型参数,优化器状态,激活函数的输出,梯度,临时缓存。
具体来说,设模型参数为\(\Phi\),模型参数(FP16)、模型梯度(FP16)以及Adam优化器状态(FP32格式的模型参数备份、FP32的momentum以及FP32的variance),总共需要 \[ 2\Phi + 2\Phi + (4\Phi + 4\Phi +4\Phi) = 16\Phi \] 字节存储。可以看到占据显存的最主要是优化器状态,为75%;
具体设计
ZeRO针对其进行gpu上的存储优化,将不同内容分片到不同的gpu上。具体来说:
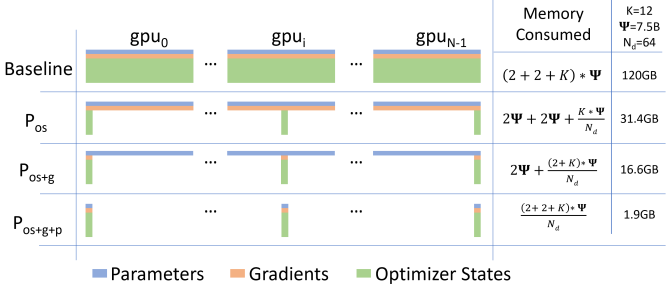
- ZeRO-1:只针对优化器状态进行分片。每张卡保存优化器状态的\(\frac{1}{N}\)。从而每张卡的显存为\(4\Phi + \frac{12\Phi}{N}\),这里记为\(P_{os}\)。当\(N\)比较大的时候,显存趋于\(4\Phi\)。
- ZeRO-2:优化器状态和梯度进行分片。那么每张卡显存为\(2\Phi + \frac{(2+12)\Phi}{N}\),这里记为\(P_{os+g}\)。那么当\(N\)比较大的时候,显存趋于\(2\Phi\)。
- ZeRO-3:优化器状态、梯度和模型参数进行分片。从而每张卡显存为\(\frac{(2+2+12)\Phi}{N}\),记为\(P_{os+g+p}\)。需要指出的是,ZeRO-3的分片并不是按照层来分,而是每一个参数矩阵flatten之后,平均划分为N份。
ZeRO-3对模型参数也进行分片,它已经是相当于数据并行加上模型并行了。
1
2
3
4
5
6
7
8
9
10W shape = [4096, 4096]
先把 W contiguous 后展平成一维:
W_flat = [w0, w1, w2, ..., w16777215]
然后按 data parallel rank 切连续区间:
rank0 保存 W_flat 的第 0 段
rank1 保存 W_flat 的第 1 段
...
rank15 保存 W_flat 的第 15 段
通信成本分析
DDP:也就是ZeRO-0,除了数据分片之外没有多余操作。那么这部分的通信成本在[[数据并行(Data Parallel)|数据并行]]部分已经分析过了:首先做
scatter-reduce聚合梯度信息,每张卡拿到各自数据分片的完整梯度信息。然后做allgather同步卡间梯度信息。两个步骤都需要做\(N-1\)次数据传输操作(\(N\)是gpu数量),每次传输量为\(\frac{\Phi}{N}\),所以总成本是\(2 \frac{N-1}{N}\Phi\)ZeRO-1:同样是先做
scatter-reduce,从而每张卡可以拿到各自分片的梯度信息。由于每张卡也只有自己分片的优化器状态信息,所以这里与DDP不同,直接更新各自分片的梯度信息即可。成本为\(\frac{N}{N-1}\Phi\)。接下来需要同步不同分片的参数信息,所以还需要再做一个关于参数的allgather操作,这一步的成本同样是\(\frac{N}{N-1}\Phi\)。从而ZeRO-1的最终通信成本与DDP是一样的: \(2 \frac{N-1}{N}\Phi\)ZeRO-2:注意到ZeRO-1的数据更新部分,每个分片只更新自己优化器状态对应部分的参数,但是却保存了完整梯度,这是没必要的,所以梯度也分片存储了。但是通信内容与成本跟ZeRO-1是完全一致的,所以最终通信成本也是\(2 \frac{N-1}{N}\Phi\)
ZeRO-3:前面几种训练方法的数据通信都发生在每一轮前向传播完之后,但是ZeRO-3由于参数本身也被分片了,在前向过程中也需要进行数据传输。前向传播部分: 数据传播到不同层时,关于该层的参数\(\Phi_{l}\)做一次
all-gather,那么每张卡通信量就是\(\frac{N-1}{N} \Phi_{l}\),所有层都做一次之后,总参数量就是\(\frac{N-1}{N}\sum_{l}\Phi_{l}=\frac{N-1}{N}\Phi\)。反向传播部分: 计算每一层梯度同样需要完整的参数信息,要做一次all-gather,所以这里的通信内容和成本与前向传播部分一致:\(\frac{N-1}{N}\Phi\)。反向传播梯度汇总: 每张卡计算得到每一层在对应数据分片下的梯度分片需要汇总,所以需要做一次scatter-reduce,那么成本也是\(\frac{N-1}{N}\Phi\)。这之后每张卡都有各自分片在所有数据分片下的完整梯度信息,ZeRO-3下也不需要做梯度同步,所以直接更新参数就可以进行下一轮训练了,这一轮也不存在其它通信成本了。最终通信成本就是\(3 \frac{N-1}{N}\Phi\)。可以看出,ZeRO-3相比前面三者,通信成本翻了1.5倍,所以这对卡间通信能力要求还是挺高的,也确实会在一定程度上拖慢训练速度。但是带来的好处也是显著的:它可以真正做到训练显存随着卡数线性减少。这在大规模训练场景下还是很有意义的。
ZeRO-offload
在使用ZeRO-1或者ZeRO-2的时候,还可以考虑将一些计算量低的操作交给cpu来处理,同时将相关信息卸载到cpu上,这可以进一步释放gpu显存。
FSDP
本质上就是 PyTorch 对 ZeRO-3 思想的官方实现。当然它也是支持cpu offload的。