DA-KD: Difficulty-Aware Knowledge Distillation for Efficient Large Language Models
提出在训练的时候,根据模型学习效果动态筛选数据集,倾向于选出学习效果较差的样本拿来训练。学习效果的依据为 \[ DDS(x) = \frac{L_{q_{\theta}}(x)}{L_{p}(x)} \] 其中\(L_{f}(x)\)代表样本\(x\)在模型\(f\)预测结果与ground truth下的ce loss
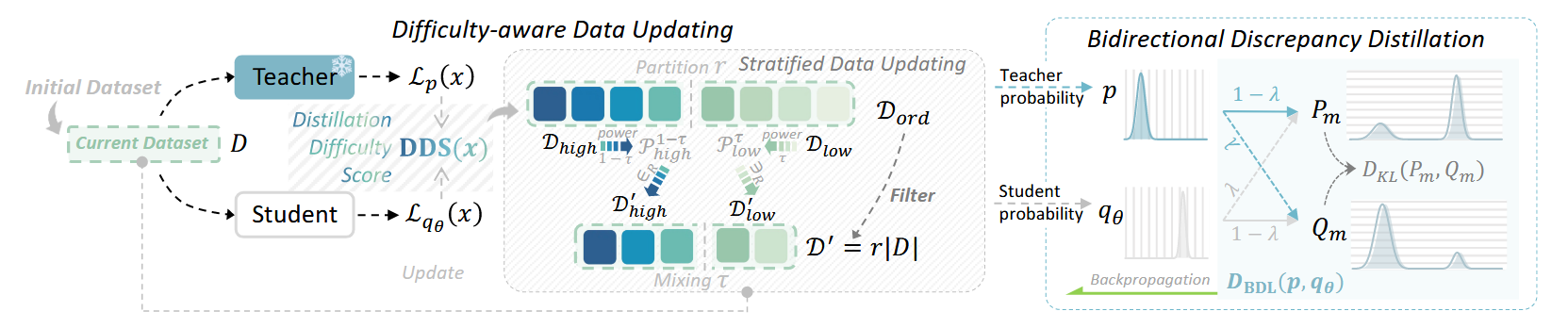
至于实际筛选策略,每次会根据样本的\(DDS\)值降序排序,然后按比重分成高\(DDS\)部分和低\(DDS\)部分,再分别从中随机采样一定数量样本,组合成新的训练数据集。
另外对loss也做了修改,参考SKL[1],得到 \[
D_{BDL}(p,q_{\theta}) = D_{KL}(((1-\lambda)p+\lambda q_{\theta})||
(\lambda p+(1-\lambda)q_{\theta}))
\] 实际上也就是把SKL和SRKL糅在了一起,此时相对参数\(\lambda\)会有一个比较稳定的上下界,梯度相对比较稳定。记\(P_{m},Q_{m}\)分别代表\((1-\lambda)p+\lambda q_{\theta}, \lambda
p+(1-\lambda)q_{\theta}\),有 
而 \[ \frac{P_{m}}{Q_{m}} = \frac{(1-\lambda)p+\lambda q_{\theta}}{\lambda p+(1-\lambda)q_{\theta}} \] 当\(p \gg q_{\theta}\)时,\(\frac{P_{m}}{Q_{m}} \rightarrow \frac{1-\lambda}{\lambda}\),当\(p \ll q_{\theta}\)时,\(\frac{P_{m}}{Q_{m}} \rightarrow \frac{\lambda}{\lambda}\) 从而\(\nabla_{\theta} D_{BDL}(p,q_{\theta})\)上下界相对稳定
Reference
[1] Ko, J., Kim, S., Chen, T., & Yun, S. DistiLLM: Towards Streamlined Distillation for Large Language Models. In ICML, 24