Distilling the Essence: Efficient Reasoning Distillation via Sequence Truncation
对推理蒸馏在数据层面进行深入分析。做推理蒸馏时,每一条数据的构成一般是: Prompt(P)+CoT+Answer(A)。然后按照一般蒸馏的方法,给定Prompt的情况下,对齐CoT+A部分。
CoT的重要性
作者通过实验发现,只需要对齐CoT部分,就能取得与整条数据都训练相当的效果,有时候甚至更好。而一旦去除CoT部分的对齐,性能就会非常低;同时在对齐CoT的情况下,再对齐P或者A,对结果基本没啥影响。
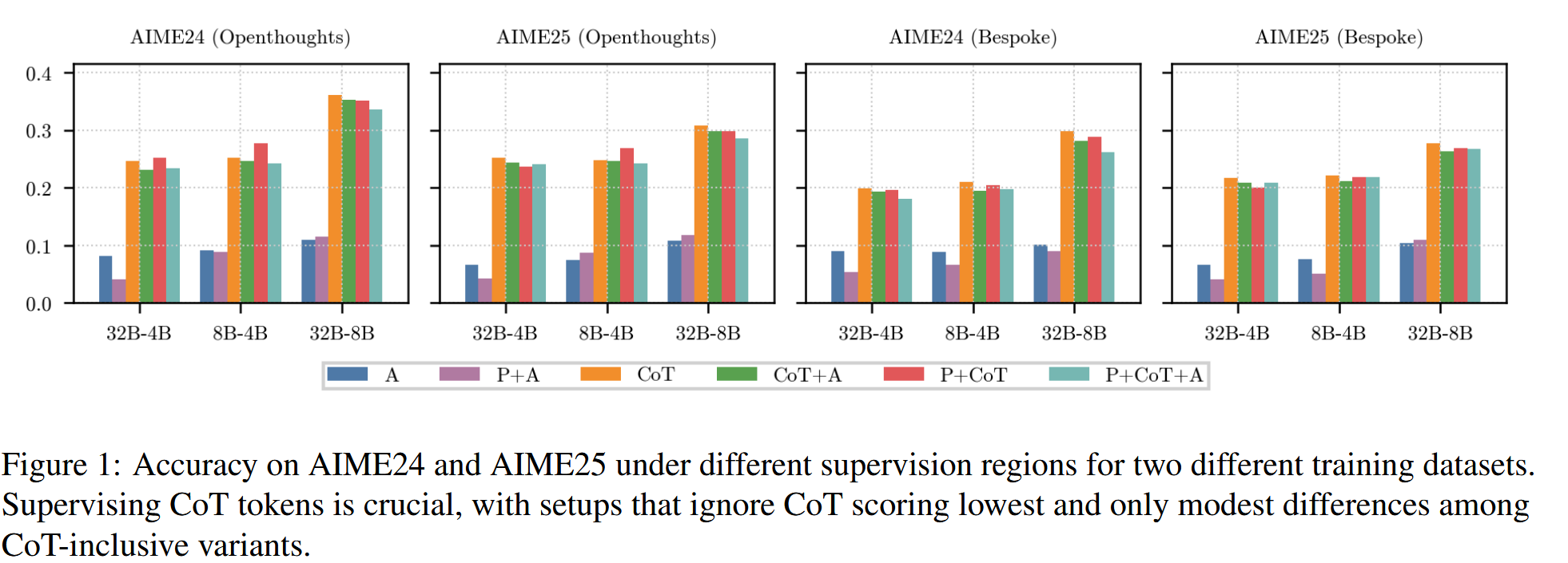
从语言分析来看,这是因为CoT当中已经基本包含了P和A的所有信息,从而再对齐P和A基本都是冗余信息了。
关于序列不同位置的信息重要性
同时,如果直接对每一条训练数据直接按照比例进行截断,也会有一些有意思的结论。具体来说,对每一条数据分别按照\(p=\{0.1, 0.2, \dots 0.9,
1.0\}\)的比例保留前\(p\)的token,后面部分直接截断,然后用于训练。
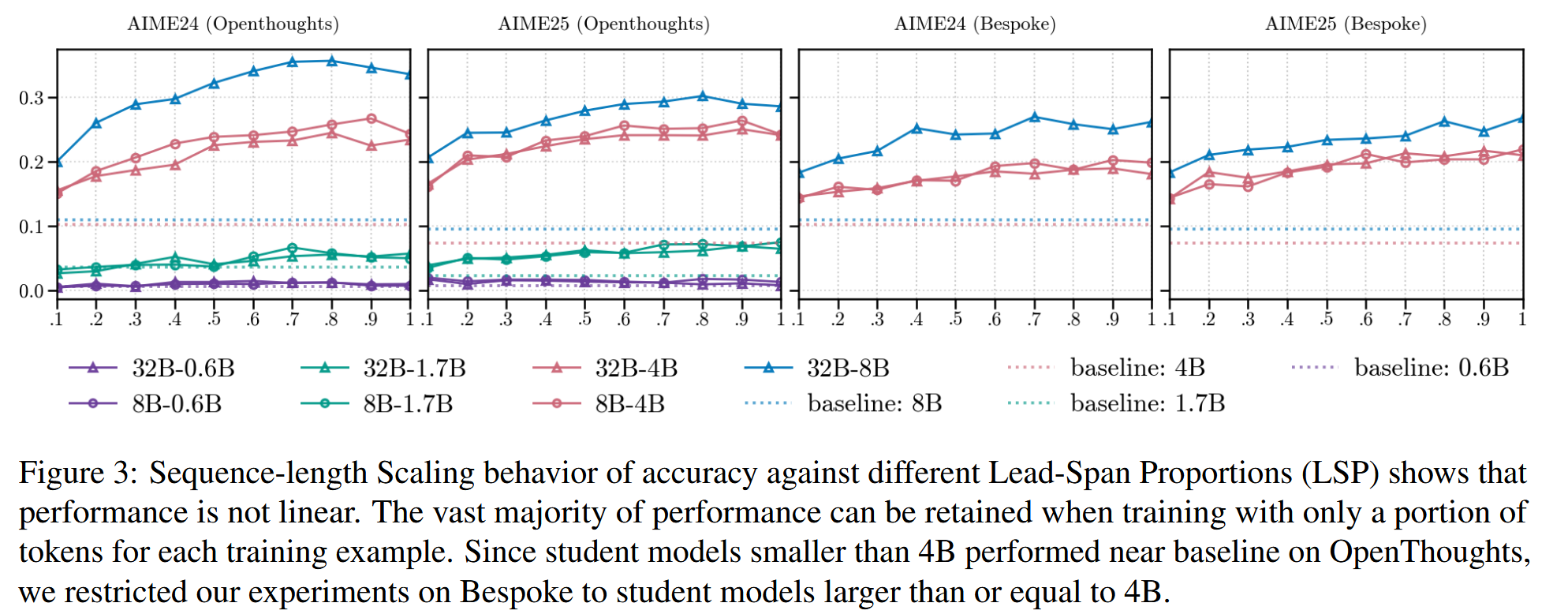
当学生模型规模比较大(大于4B)时,观察到训练效果最好的时候反而不是在\(p=1\)时取得,这一点与上一个结论有一定联系,因为我们知道A的信息基本是冗余的。但是只取\(p=0.5\)左右长度的数据,也能取得不错的性能,这意味着推理前期所获得的信息,相比后期,是要更多的。当然,当模型规模比较小的时候,这一点并不明显。
不过感觉这里实验可能也并非足够合理,对于小的模型(0.6B,1.7B)来说,8B和32B实在是太大了,从中收益有限(实际是基本蒸了等于没蒸,尤其是0.6B)。如果选择更合理的教师,这里关于它们的结论可能会有些不同。
作者直接对数据按照\(p=0.5\)分成左右两部分,然后分别训练,结果表明,只用前半部分所能得到的效果,确实是要远好于后半部分的。
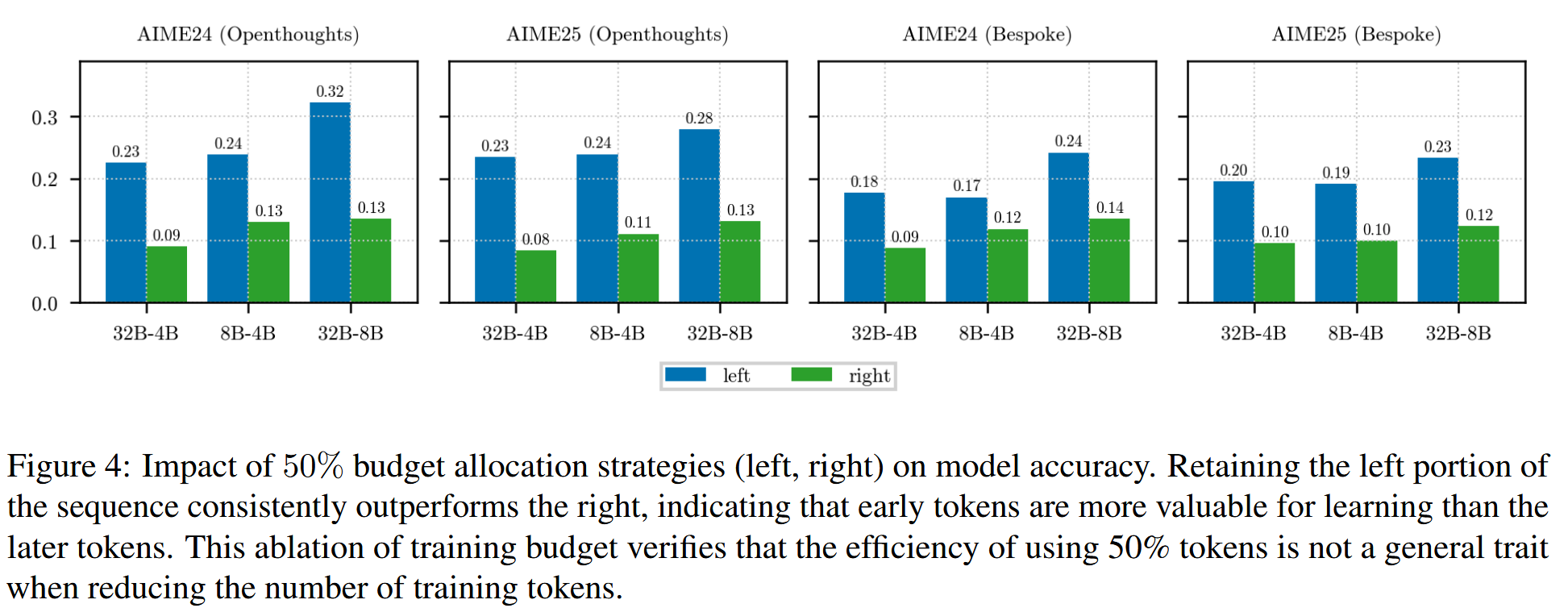
对于这一点,作者认为是因为在推理前期,基本可以第一次得到答案了,后半部分往往是在反复验证,或者干脆就是无益的过度推理。
这启示我们,当学生模型规模比较大的时候,可以尝试直接对训练数据按照\(p=0.5\)的比例进行截断。这一操作的益处是相当明显的:一方面学生和教师的规模都不小,另一方面,推理数据,由于CoT的存在,都是相当长的,这会带来巨大的KV
cache,以及显存压力,这一点可以在下图中看到。 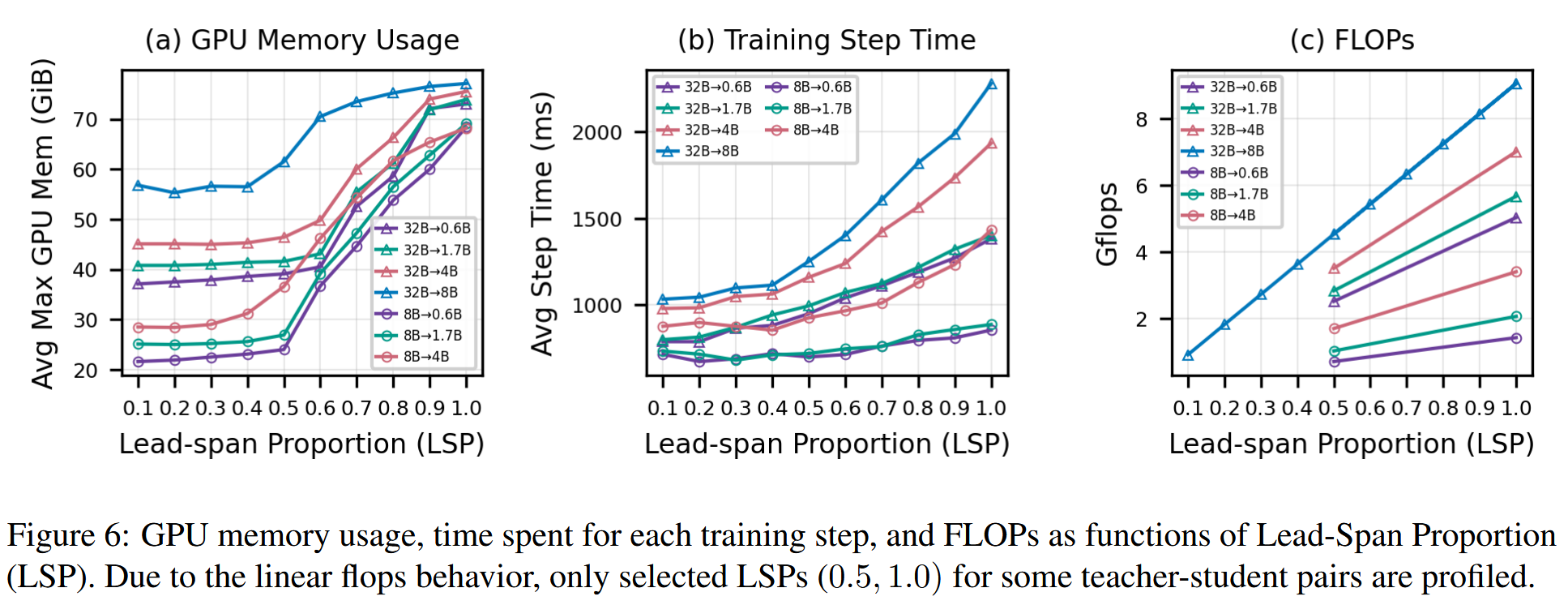
\(p<0.5\)时,不管是显存压力,还是训练时间,都没有明显增长。但是\(p>0.5\)时,由于attention的平方复杂度,训练压力会直线上升。但是根据前面实验的结果,此时我们的训练效果并不会有很多提升。
Conclusion
蒸馏的时候,直接用CoT,就可以取得与原本基本一致的效果 学生规模较大(>4B)时,对蒸馏数据按照\(p=0.5\)截断,训练压力会下降很多,同时保持不错的训练效果。(这一结论在小模型上效果不明显,但我认为可能是实验设置不合理导致的,保留意见)