Connections Between On Policy Distillation And RL
对[1]的阅读笔记。
Main
早期LLM post training策略,一个是off policy的SFT/KD,一个是on policy的RL 对于SFT来说,其对于每一个token都有监督信号,训练稳定性好,但是训练数据集分布固定,容易导致train-inference mismatch;对于RL,其直接优化当前策略,但是不稳定,并且常常面临奖励系稀疏、延迟、高方差的问题
on-policy distillation(OPD)结合的两者的优点,并且同时规避了各自的缺点。这篇文章尝试描述OPD与RL之间在损失函数,梯度形式上的联系。
RL的损失函数表述如下 \[ \mathcal{J}_{RL}(\theta) = \mathrm{max}_{\theta}\ \mathbb{E}_{x\sim D, y\sim \pi_{\theta}(\cdot|x)} \left[r(x,y) - \beta\mathcal{D}_{KL}(\pi_{\theta}(y|x)||\pi_{ref}(y|x)) \right] \tag{1} \] 其中\(x\)代表prompt,在此基础上生成response \(y\) 。\(\mathcal{J}_{RL}\) 的梯度可以表示为 \[ \nabla_{\theta}\mathcal{J}_{RL}(\theta) = \mathbb{E}_{x\sim D, y\sim \pi_{\theta}(\cdot|x)} \left[ \sum_{t=1}^{T} A_{t}\nabla_{\theta}\log \pi_{\theta}(y_{t}|x,y_{<t}) \right]\tag{2} \] 其中\(A_{t}\)代表每一个token的优势。事实上由于nlp场景下一个句子往往只能在输出结束后获得奖励\(r(x,y)\),所以RL经常面临奖励稀疏的问题,进而导致credit assignment等问题。 对于OPD来说,其损失函数表述为 \[ \mathcal{J}_{OPD}(\theta) = \mathrm{min}_{\theta} \ \mathbb{E}_{x\sim D,y\sim \pi_{\theta}(\cdot|x)} \left[ \mathcal{D}_{KL}(\pi_{\theta}(y|x)||\pi^*(y|x)) \right]\tag{3} \] 这里默认其使用的是SRKL。相对应的,\(\mathcal{J}_{OPD}\) 的梯度表示为 \[ \nabla_{\theta}\mathcal{J}_{OPD}(\theta) = \left[ \sum_{t=1}^{T} (\log \frac{\pi_{\theta}(y_{t}|x,y_{<t})}{\pi^*(y_{t}|x,y_{<t})}) \nabla_{\theta}\log \pi_{\theta}(y_{t}|x,y_{<t}) \right]\tag{4} \] 如果将式\((2)\)与式\((4)\)放在一起对比,不难看出,OPD相对RL,提供了一个token-level的,相对更加dense的权重信息,或者说优势信息。如果对\(\mathcal{J}_{OPD}\)进行变形,两者之间的联系会更加清晰 \[ \begin{flalign} \mathcal{J}_{OPD}(\theta) &= \mathrm{min}_{\theta} \ \mathbb{E}_{x\sim D,y\sim \pi_{\theta}(\cdot|x)} \left[ \mathcal{D}_{KL}(\pi_{\theta}(y|x)||\pi^*(y|x)) \right] \\ &= \mathrm{min}_{\theta} \ \mathbb{E}_{x\sim D,y\sim \pi_{\theta}(\cdot|x)} \left[ \log\pi_{\theta}(y|x) -\log \pi^*(y|x)) \right] \\ &= \mathrm{min}_{\theta} \ \mathbb{E}_{x\sim D,y\sim \pi_{\theta}(\cdot|x)} \left[ (\log\pi_{\theta}(y|x) - \log \pi_{ref}(y|x)) -( \log \pi_{ref}(y|x) - \log \pi^*(y|x)) \right] \\ &= \mathrm{max}_{\theta} \ \mathbb{E}_{x\sim D,y\sim \pi_{\theta}(\cdot|x)} \left[ \log \frac{\pi^*(y|x)}{\pi_{ref}(y|x)} - \mathcal{D}_{KL}(\pi_{\theta}(y|x)||\pi_{ref}(y|x)) \right] \\ \end{flalign} \tag{5} \] 第二步到第三步引入了一个ref model,当然其会被消掉,因此其选择实际上并没有限制。
将式\((5)\)与式\((1)\)进行对比之后就可以看到
OPD其实就是一种特殊形式的RL
两者之间关系紧密,而区别主要体现在一下几点
奖励信息不同 对于原始的RL来说,其奖励\(r_{t}\)相当稀疏,只有输出最后一个token之后,才能获得奖励信息。 \[ r_{t}^{RL} = \begin{cases} 0 , & t < T \\ \text{sentence reward}, & t=T \end{cases}\tag{6} \] 相比之下,OPD提供的奖励是token-level的 \[ r_{t}^{OPD} = \log \frac{\pi^*(y_{t}|x,y_{<t})}{\pi_{ref}(y_{t}|x,y_{<t})}, t \leq T \tag{7} \] 其含义是best strategy(即KD场景下的教师模型)与 reference strategy之间的log-probability shift信息。这自然地解决了RL面临的奖励稀疏的问题。 [2]实际上有指出,对于\((1)\)来说,最优奖励形式为 \[ r^*(x,y) = \beta \log \frac{\pi^*(y|x)}{\pi_{ref}(y|x)} + \beta \log Z(x)\tag{8} \] 其中\(Z(x)\)是常数,代表归一化项,忽略之后,其实恰好就是OPD的奖励形式。
对于OPD来说,其reference model并不是固定的,可以任意选取。而在RL中,这个reference model往往代表模型优化前的初始参数。
对于OPD,其奖励项与KL项之间的系数是固定的1,而这实际上是可以被打破的
因此,OPD相比于RL,有两点优势:dense reward,flexible choices of reference model
而对于第三点,可以直接尝试添加超参来打破两者之间固有的系数比例,从而得到新的OPD Loss \[ \begin{flalign} \mathcal{J}_{G-OPD}(\theta) &= \mathrm{max}_{\theta} \ \mathbb{E}_{x\sim D,y\sim \pi_{\theta}(\cdot|x)} \left[ \textcolor{red}{\lambda} \log \frac{\pi^*(y|x)}{\pi_{\textcolor{blue}{ref}}(y|x)} - \mathcal{D}_{KL}(\pi_{\theta}(y|x)||\pi_{\textcolor{blue}{ref}}(y|x)) \right] \\ \end{flalign} \tag{9} \] 接下来尝试分析\(\lambda\)的实际含义。这里\(\lambda\)等价于\((1)\)中\(\beta=\frac{1}{\lambda}\)的情况,参考[2],对于\((1)\)来说,学生模型的最优参数形式为 \[ \pi_{\theta}(y|x) = \frac{1}{Z(x)}\pi_{ref}(y|x)\exp\left( \frac{1}{\beta}r(x,y) \right) \tag{10} \] 在OPD中,代入奖励为\(r^{OPD}= \log \frac{\pi^*(y|x)}{\pi_{ref}(y|x)}\),以及\(\beta=\frac{1}{\lambda}\)之后,得到 \[ \begin{flalign} \log \pi_{\theta}(x) &= \log \pi_{ref}(y|x) + \lambda \log \frac{\pi^*(y|x)}{\pi_{ref}(y|x)} - \log Z(x)\\ &= \lambda \log \pi^*(y|x) + (1-\lambda) \log \pi_{ref}(y|x) \\ &= \log \pi^*(y|x) + (\lambda-1) (\log \pi^*(y|x) - \log \pi_{ref}(y|x)) \end{flalign} \tag{11} \]
进一步观察\(\lambda\)取不同值的时候,最优学生模型参数,或者说学生的学习目标,会有什么变化
- \(0<\lambda<1\)时,学习目标在教师模型和ref model之间做了一个插值
- \(\lambda=1\) 的时候, 第二项偏差项消失,此时学生的学习目标严格等于教师模型,这也是原始的OPD的形式
- \(\lambda>1\)时,学生除了学习教师模型,还会额外学习教师与ref model之间的偏差,此时称为奖励外推
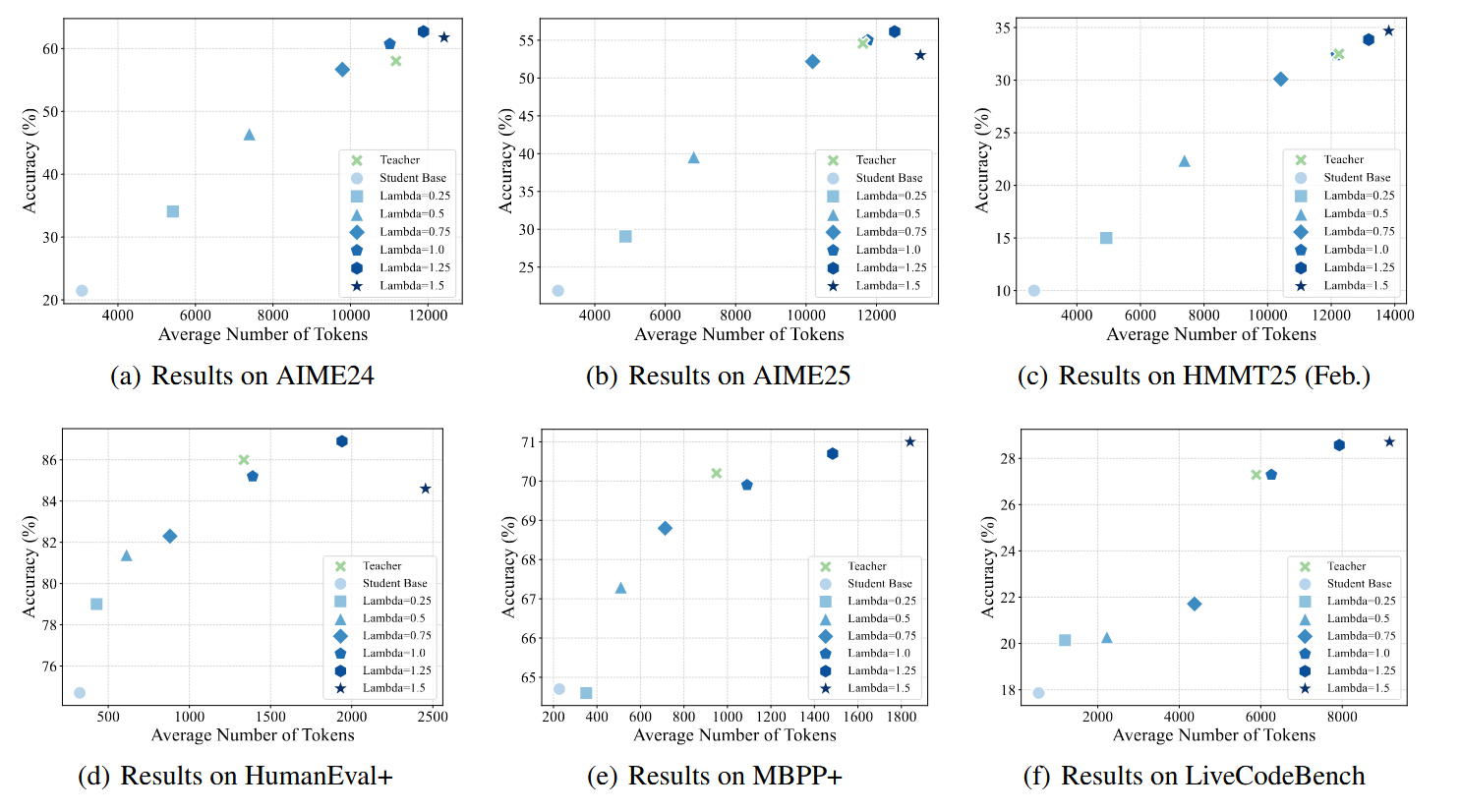
从实验上来看,\(\lambda \leq 1\)时,蒸馏效果随\(\lambda\)单调增,但是基本不太能超过教师。而\(\lambda>1\)之后,可以超过教师,但\(\lambda\)过大(>=1.5)之后,效果可能不如。作者指出,当\(\lambda>1\)时,这种外推的形式,在多教师蒸馏场景下,统一训出的学生,可以做到超越所有领域的教师。
还有一个非常有意思的问题是:当\(\lambda \neq 1\)时,ref model的选择是否有讲究?因为前面已经提过,OPD的形式中的ref model的选择实际上并没有严格限制。 作者提了两个选择:原始学生模型\(\pi_{base}^{S}\),优化前的教师模型\(\pi_{base}^{T}\)。在单纯的strong-to-weak场景下,以往的直觉可能是原始学生模型,但是作者指出以优化前的教师模型\(\pi_{base}^{T}\)作为ref model可能会是一个更好的选择。 \[ \begin{flalign} \mathcal{J}_{G-OPD}(\theta) &= \mathrm{max}_{\theta} \ \mathbb{E}_{x\sim D,y\sim \pi_{\theta}(\cdot|x)} \left[ \lambda \log \frac{\pi^*(y|x)}{\pi_{ref}(y|x)} - \mathcal{D}_{KL}(\pi_{\theta}(y|x)||\pi_{ref}(y|x)) \right] \\ &= \mathrm{max}_{\theta} \ \mathbb{E}_{x\sim D,y\sim \pi_{\theta}(\cdot|x)} \left[ \lambda (\log \pi^*(y|x) - \log \pi_{ref}(y|x)) - \pi_{\theta}(y|x) + \log \pi_{ref}(y|x) \right] \\ &= \mathrm{max}_{\theta} \ \mathbb{E}_{x\sim D,y\sim \pi_{\theta}(\cdot|x)} \left[ (\lambda-1) (\log\pi^*(y|x) - \log \pi_{ref}(y|x)) - (\pi_{\theta}(y|x) - \log \pi_{*}(y|x) \right] \\ &= \mathrm{max}_{\theta} \ \mathbb{E}_{x\sim D,y\sim \pi_{\theta}(\cdot|x)} \left[ (\lambda-1) \log \frac{\pi^*(y|x)}{\pi_{ref}(y|x)} - \mathcal{D}_{KL}(\pi_{\theta}(y|x)||\pi_{*}(y|x)) \right] \\ \end{flalign} \tag{12} \] 此时KL项与\(\pi_{ref}\)无关,我们可以只关注不同ref model的选择对奖励信号的影响。如果选择\(\pi_{base}^T\)的话, \(\mathcal{J}_{OPD}\)的奖励为\(\log \frac{\pi^*(y|x)}{\pi_{base}^T(y|x)}\),参考式\((8)\)这实际上是教师在做RL时的隐藏奖励信号,相当于学生是在学习一个相对的从base到微调后的增量价值信号。相比之下,\(\pi_{base}^S\)与\(\pi^*\)的差距过大,并且往往可能包含更多噪声,比如架构偏差,表达风格等,这些是与推理能力提升无关的。
需要指出的是,选择\(\pi_{base}^T\)作为ref
model时,要求能够访问到\(\pi_{base}^T\),这在某些场景下可能是不行的,并且使用\(\pi_{base}^T\),相比\(\pi_{base}^S\),计算压力会更大一些,毕竟其规模更大。
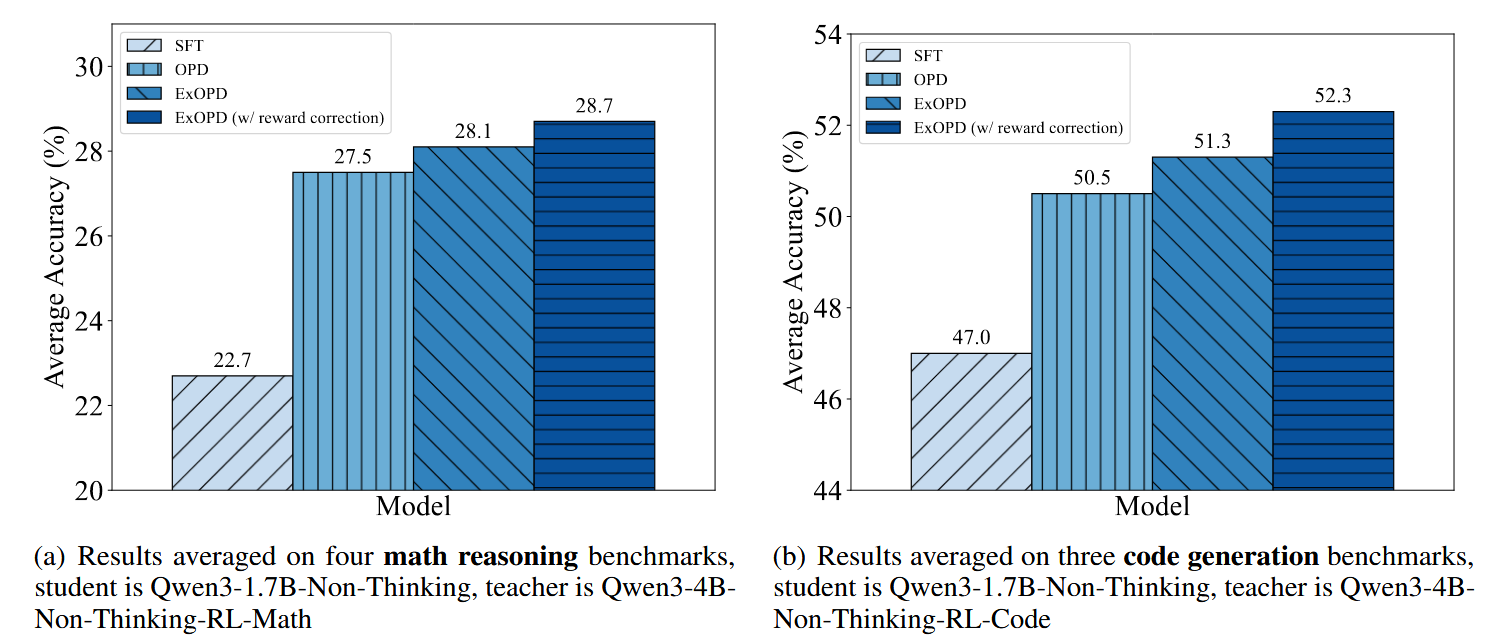
从实验结果来看,使用\(\pi_{base}^T\)的效果(w/ reward correction)确实会更好一些,但是考虑到其计算压力以及访问限制,与\(\pi_{base}^S\)还是需要权衡使用。
Conclusion
OPD可以看成一种特殊的RL,其奖励是token-level的\(\log \frac{\pi^*(y_{t}|x,y_{<t})}{\pi_{ref}(y_{t}|x,y_{<t})}\),相比RL可以有效缓解奖励稀疏问题。原始OPD的奖励项和KL项系数固定,通过解耦,改变系数,可以有更好的效果。最后是ref model的选择问题,使用\(\pi_{base}^T\),相比于\(\pi_{base}^S\),效果更好,但是计算成本更大,适合用于尝试蒸馏的极限性能。
最后,本文总共出现了三种训练手段: * 传统OPD:学生生成SGO,教师和学生在SGO上生成对应token的概率分布,并进行对其 * G-OPD:损失函数使用\(\mathcal{J}_{G-OPD}\),引入ref model为\(\pi_{base}^{S}\),计算成本稍微大一点 * G-OPD(reward correction):ref model使用\(\pi_{base}^T\),计算成本大,且需要保证能访问\(\pi_{base}^T\),但是效果好
Reference
[1] Yang, W., Liu, W., Xie, R., Yang, K., Yang, S., & Lin, Y. (2026). Learning beyond Teacher: Generalized On-Policy Distillation with Reward Extrapolation.
[2] Rafailov, R., Sharma, A., Mitchell, E., Ermon, S., Manning, C.D., & Finn, C. (2023). Direct Preference Optimization: Your Language Model is Secretly a Reward Model. ArXiv, abs/2305.18290.