Distilling the Knowledge in Data Pruning
原本对训练dataset进行pruning之后直接进行模型训练就结束了,本文提出,原本的基于全dataset训练的模型可以作为Teacher,对在pruned dataset上训练的Student进行蒸馏,这会取得更好的效果。 首先介绍一下Dataset Pruning,这其实与Weight Pruning是类似的,都是对基本组成元素定义一个重要性,然后依据重要性进行pruning。同时定义剪枝比例\(f = \frac{N_{f}}{N}\)代表保留的数据比例,其中\(N,N_{f}\)分别代表原始数据集大小,剪枝后的数据集大小 整体Loss表示为 \[ L_{\theta} = (1-\alpha) L_{cls}(\theta) + \alpha L_{KD}(\theta) \] 其中前者代表学生在pruned dataset上训练的CE Loss,后者代表教师与学生的KD Loss。这里\(\alpha\)的设计也有点意思。事实上随着剪枝比例\(f\)的降低,留下的都是一些学习难度较大的样本,其中的噪声较多,此时在全dataset上训练过的教师就能提供很好的指导作用[1]。因此\(f\)降低时,KD所占的权重应当扩大,即\(\alpha\)与\(f\)应当是成反比的。 至于在构造pruned data的时候,具体的pruning策略,作者直接选择了随机pruning。这是因为作者发现,在加入KD之后,与复杂的修剪方法相比,在使用简单随机修剪的同时结合 KD 可以达到相当或更高的准确性。
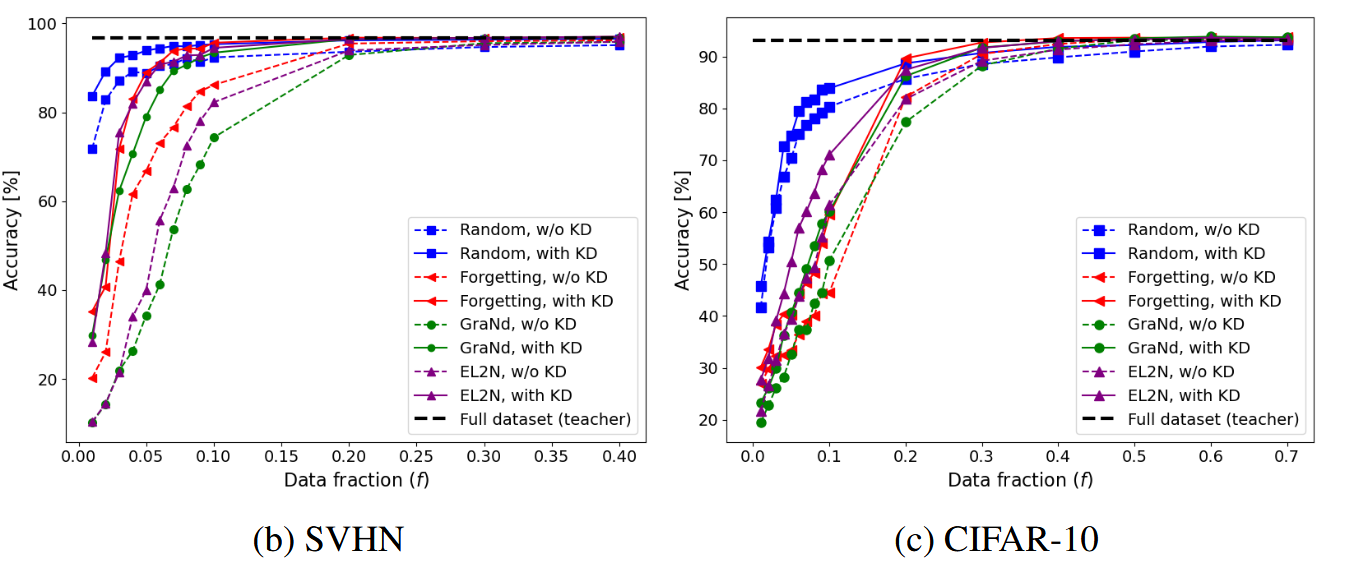
这一点还是很有意思的。
训练时还有一个有意思的现象 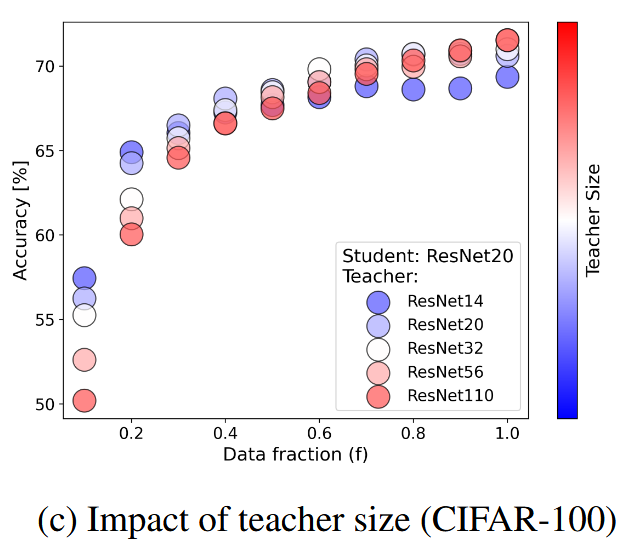 当剪枝比例\(f\)比较低的时候,面对同一个学生,用规模较低的教师对其进行蒸馏反而有更好的效果,并且这一现象关于蒸馏温度是鲁棒的。这其实有点反直觉,作者也没有给出很好的解释。不过这一现象在\(f\)较高的时候就不存在了。
当剪枝比例\(f\)比较低的时候,面对同一个学生,用规模较低的教师对其进行蒸馏反而有更好的效果,并且这一现象关于蒸馏温度是鲁棒的。这其实有点反直觉,作者也没有给出很好的解释。不过这一现象在\(f\)较高的时候就不存在了。
总体来说,引入KD之后,对dataset的pruning策略可以变得异常简单(完全随机pruning)而不会带来显著的模型性能下降(甚至还有上升)。不过其实也可以直接从KD的视角来观察这一训练范式:它其实就是在教师训练好之后,对教师训练用的dataset进行pruning,然后直接做KD。 从这一视角来看,做dataset pruning可能就显得有些多余了,不如直接做KD?
Reference
[1] Das, R., & Sanghavi, S. (2023). Understanding Self-Distillation in the Presence of Label Noise.