Massive Activations in Large Language Models
Massive Activation
探究了LLM中的massive activation。
LLM中某些activation具有巨大的magnitude,其值比普通activation的多了好几个数量级,并且它们的数量相当稀少,在每个模型中基本只有2-4个,但是确实是普遍存在的
关于这种massive activation的存在:往往是在某一层之后突然就出现的,然后会一直持续,在末尾几层消失
"we have shown that their values largely stay constant in middle layers"
"Massive activations exist and remain as largely constant values throughout most of the intermediate layers. They emerge in the initial layers and start to diminish in the last few layers"
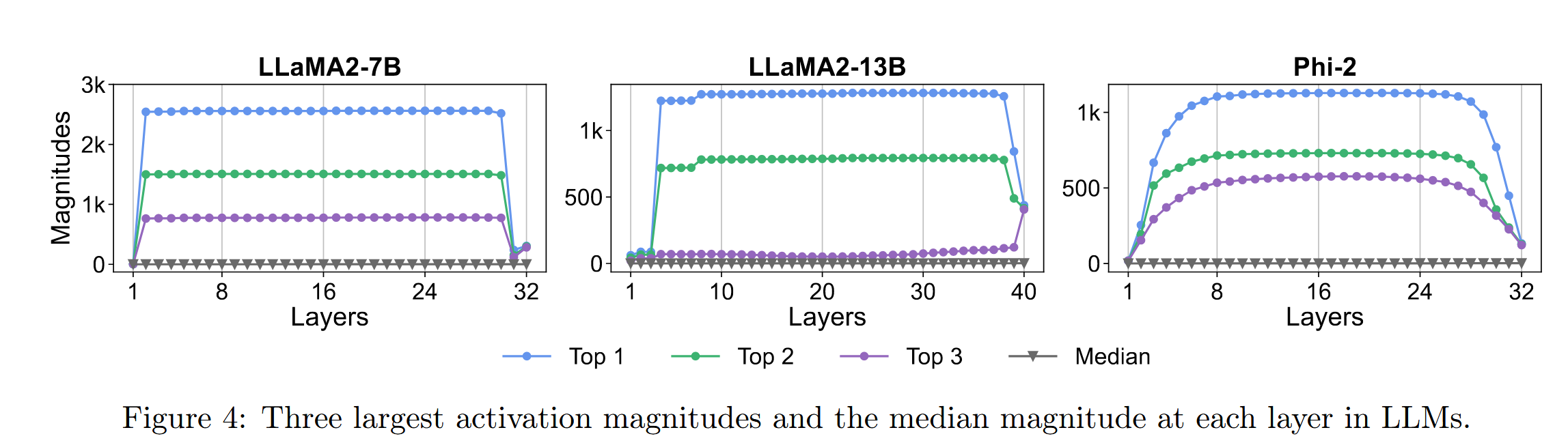 这意味着它们不是通过多层逐渐积累的结果,而是由其它机制引起的
这意味着它们不是通过多层逐渐积累的结果,而是由其它机制引起的
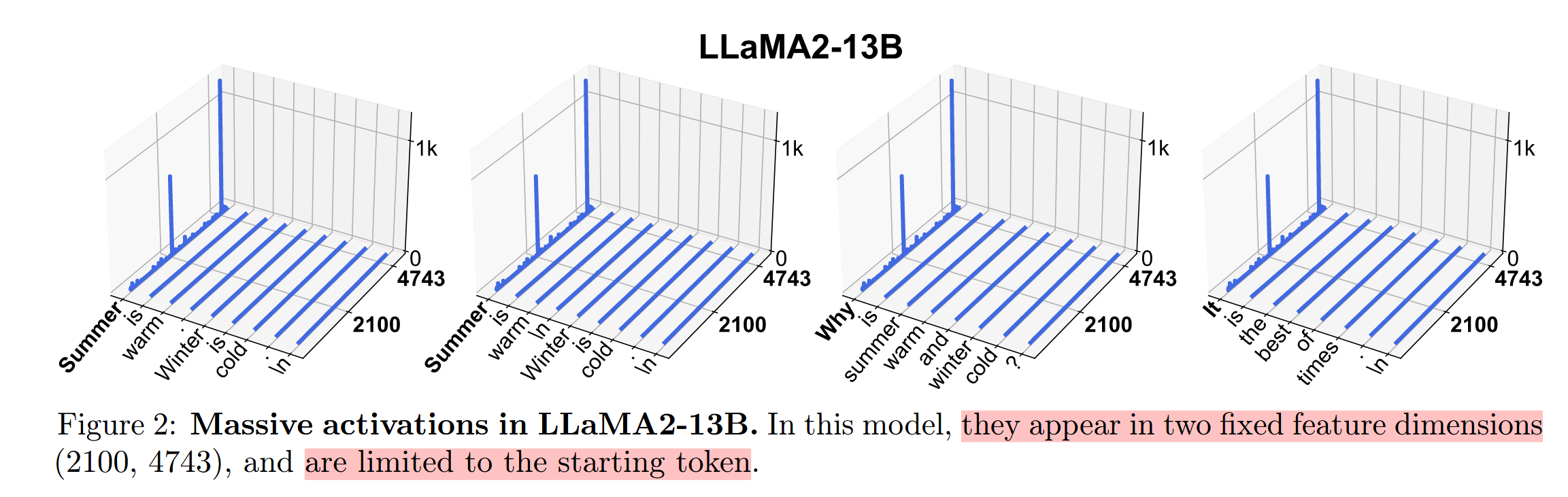
从feature的角度来看,它们往往出现在较少且固定的维度上
从token的角度来看,这种massive
activation往往出现在起始token以及分隔符等位置 3.
关于它们的作用,作者分别做了两种对比实验:在其第一次出现的时候,将其置为0,或者直接置为不同输入下的经验平均值
3.
关于它们的作用,作者分别做了两种对比实验:在其第一次出现的时候,将其置为0,或者直接置为不同输入下的经验平均值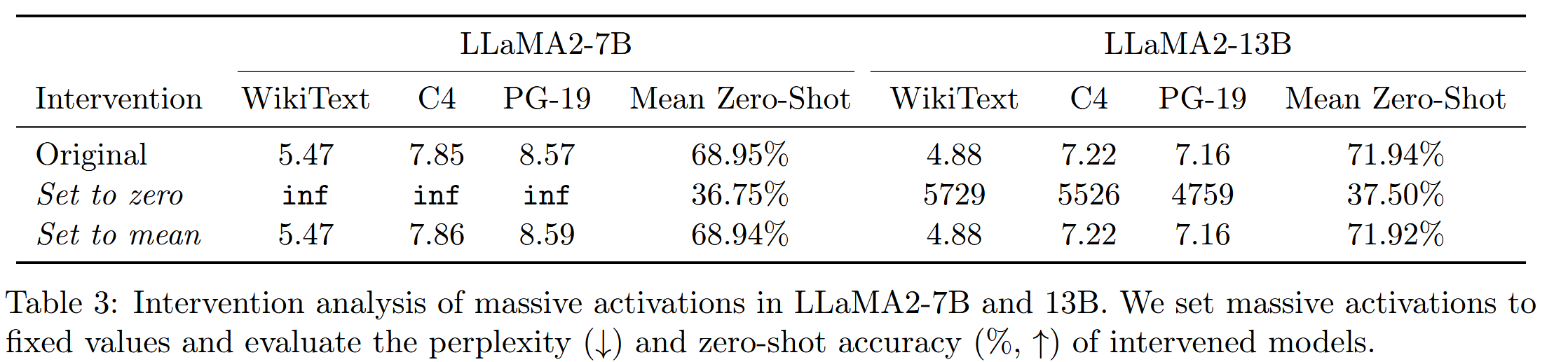 不难看出,将这些极少数的维度置为0,带来了毁灭性的性能下降,但是将其鲁莽地置为平均值,几乎没有带来性能下降,这意味着这种activation的值是相当稳定的,并且几乎不随输入而变化,所以作者将其视为模型中的固定且重要的偏差。
不难看出,将这些极少数的维度置为0,带来了毁灭性的性能下降,但是将其鲁莽地置为平均值,几乎没有带来性能下降,这意味着这种activation的值是相当稳定的,并且几乎不随输入而变化,所以作者将其视为模型中的固定且重要的偏差。
从这一角度可以尝试理解为什么massive
activation往往出现在起始token以及分隔符等位置。对于分隔符,其往往没有具体含义,从而适合存储此类偏差。而如果在一些具有丰富语义的token上存储massive
activation的话,可以导致输入信息的丢失。对于出现在起始token,作者的解释为
Effects on Attention
attention sink现象是指self
attention的注意力权重中,大部分都集中在第一个token上,而这一现象也可以与Massive
Attention关联 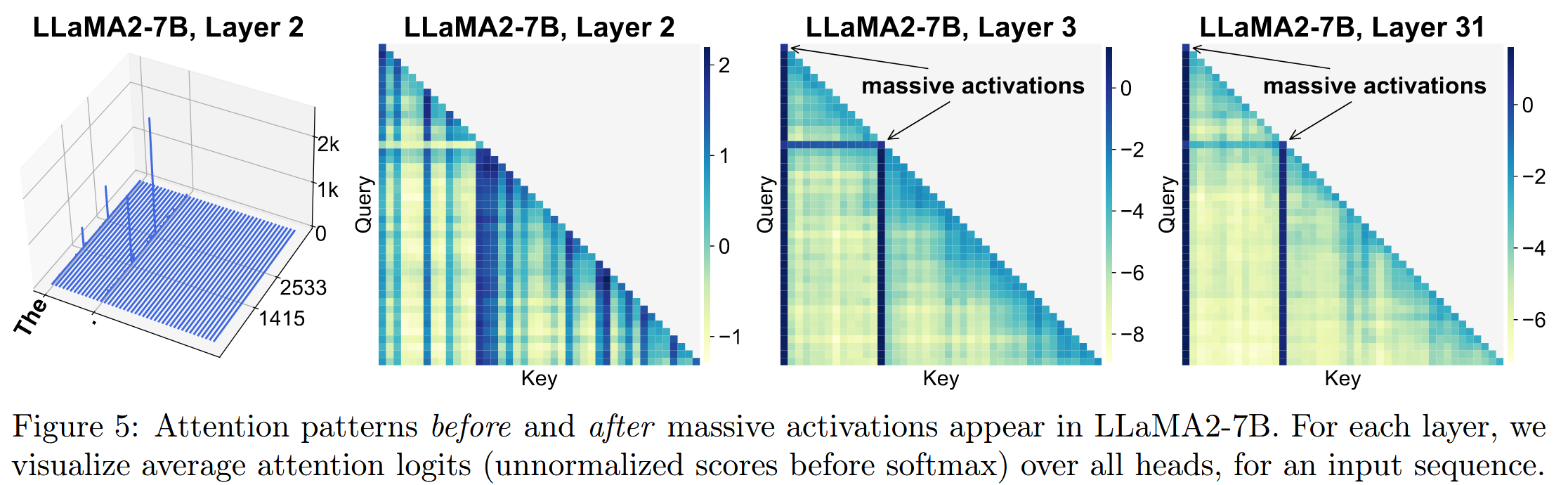
不难看出,实际上注意力分数较高的部分,都是与massive activation相关联的token,这为attention提供了新的解释
事实上,如果将massive
activation对应维度对注意力分数的贡献提取出来(关于某个token
k),其分布也基本是不变的,这为之前的bias的说法提供了依据。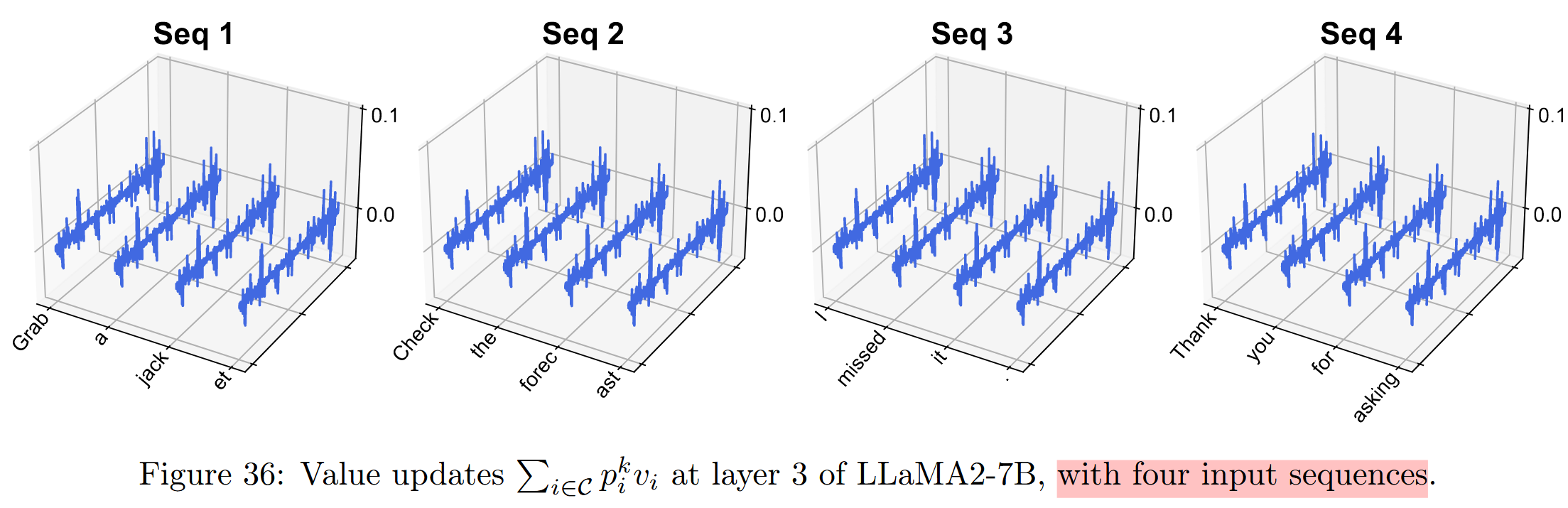 可以看到,其分布在不同输入中高度一致,同时在不同token中也高度一致,一方面说明其稳定性,另一方面印证了其作为统一的bias的作用。这种说法还是挺有意思的。
可以看到,其分布在不同输入中高度一致,同时在不同token中也高度一致,一方面说明其稳定性,另一方面印证了其作为统一的bias的作用。这种说法还是挺有意思的。