Evaluating Position Bias in Large Language Model Recommendations
指出LLM
Rec的时候,模型给出的推荐结果可能会受到item输入顺序的影响。输入的prompt格式如下
1
Based on the user’s preferences, can you rank the following items, item1, item2,...?
接下来先看看作者是如何尝试降低input position bias对模型的影响的 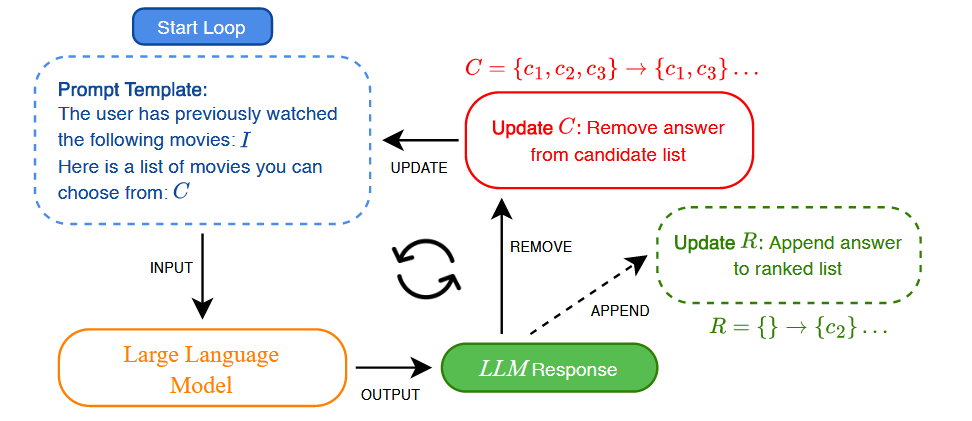
设计非常直观,每次推荐时只取出推荐序列的top1,然后将剩下的item重新给llm进行推荐任务,最后将n-1次推荐结果合在一起得到最终推荐结果。如果一次性给n个item排序太难的话,就把任务进行拆解。这里每次只取出top1,记为RISE@1
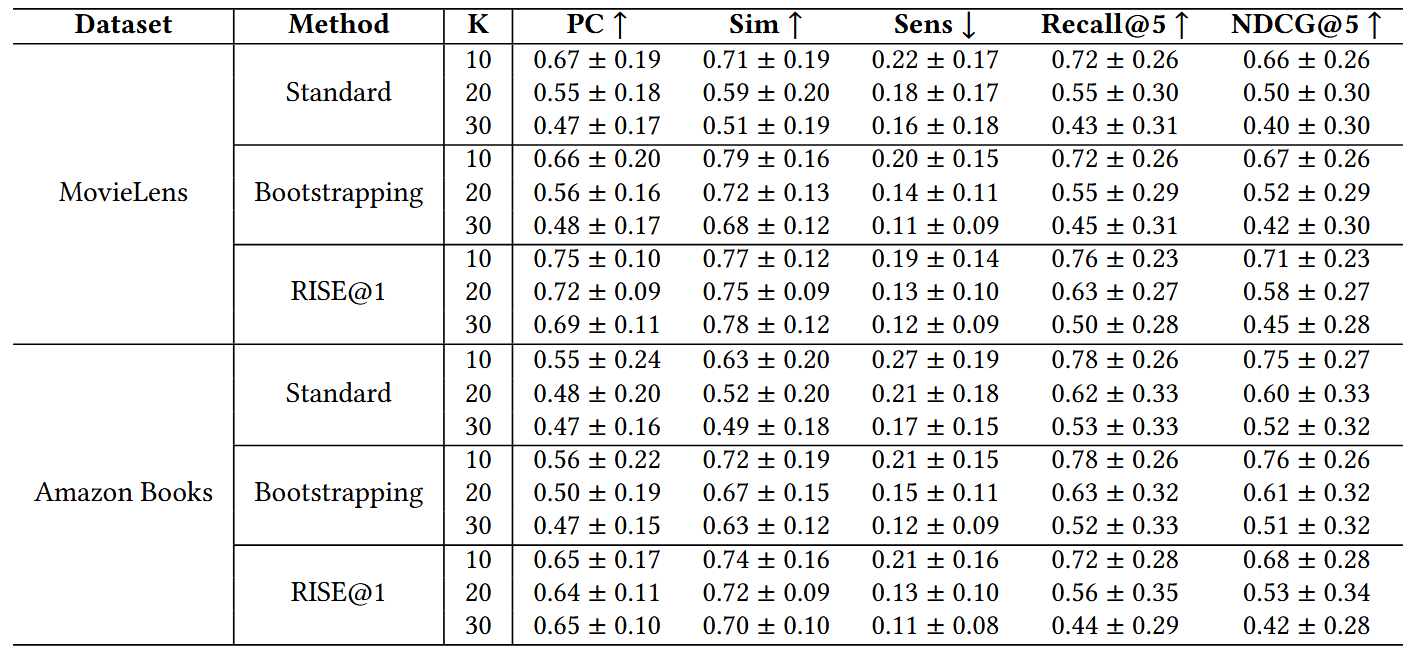
这里\(K\)代表序列长度,Positional Consistency (PC),Output Similarity (Sim)的含义如前所述。首先可以看到RISE@1在缓解input position bias上确实是有帮助的,只是其在Amazon Books上的推荐效果(Recall, NDCG)反而落后挺多,说服力不是很足。
总之,本文提出模型在推荐任务中得到的结果会受到input position bias的影响,并指出对推荐任务进行拆解有助于缓解该现象。 但是没有尝试解释这一现象的内在原因,以及其具体是如何影响推荐性能的。这个bias本身的描述也不甚清晰,推荐结果中两个item之间的相对顺序的改变,是只受到它们在input中相对顺序的影响吗,还是与其它item也有关? 不过现象本身还是挺有意思的。