Squeeze, Recover and Relabel: Dataset Condensation at ImageNet Scale From A New Perspective
以往的dataset
distillation都是基于耦合的双层优化的,内层优化模型关于synthetic
dataset的参数,外层优化synthetic
dataset。但是当原始数据集很大/模型很大的时候,这一双层优化过程的速度就会很慢。作者提出对这一过程进行解耦,从而将原本的平方复杂度降低至线性。
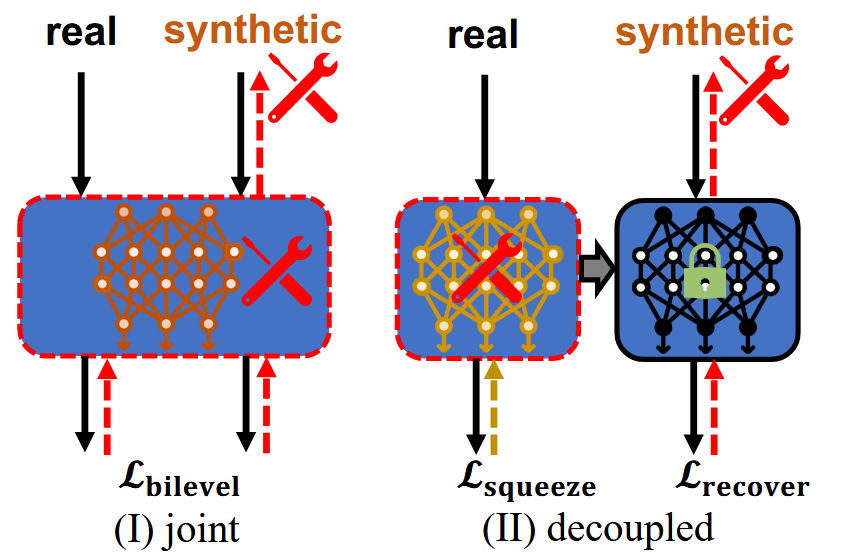
其阶段可以分为三个部分 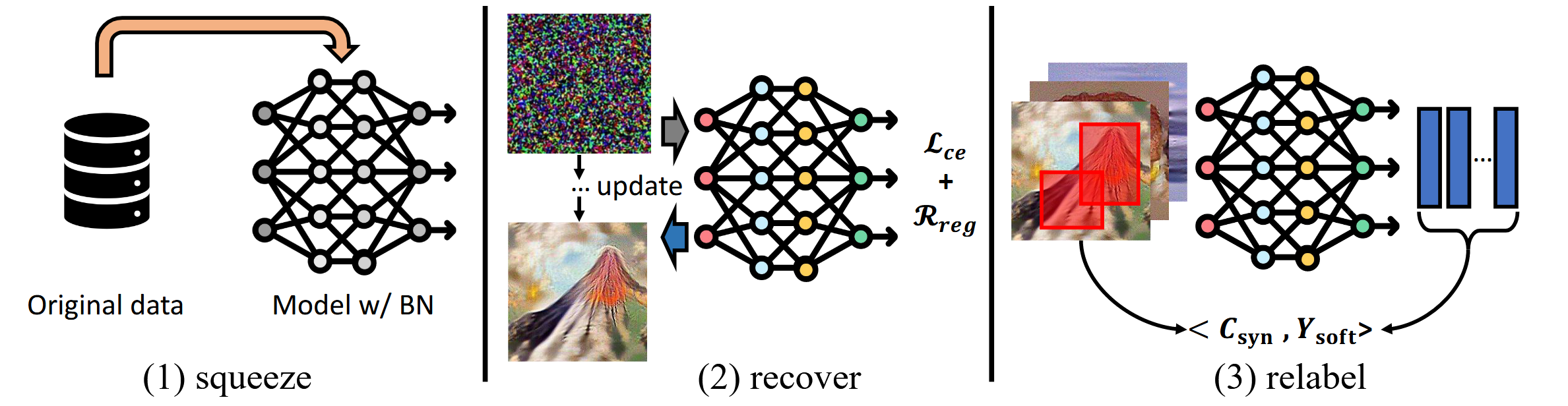
首先进行数据集信息的凝练,将其存入模型参数中。 \[ \theta_{T} = argmin_{\theta}L_{T}(\theta)\tag{1} \] 这一步实现起来并没有多余设计,就是让模型在原始数据集上进行训练,并冻结参数。不过作者指出,数据集的一部分重要信息,是由BN中的mean和variance记录的,因此后续需要用BN的信息进行对齐。但是ViT中使用的是Layer Norm,因此作者也将其修改为BN。注意这里模型在数据集上训练的目的是存储数据集信息,而不是单纯跑到最优性能,因此将ViT的Norm手段修改为BN,虽然性能会掉,但是是可以接受的。
其次,就是用上一步凝练得到的数据集信息,还原回合成数据集 \[ argmin_{C_{syn}} l(\Phi_{\theta_{T}}(\tilde{X}_{syn}, y)) + R_{reg}\tag{2} \] \((2)\)式中第一部分就是上一步冻结参数的模型\(\theta_{T}\)在合成数据集\(C_{syn}\)的一个batch \(\tilde{X}_{syn}\)上的loss,第二部分是正则化项。注意这里\(\theta_{T}\)是被冻结的,因此是在单纯优化\(C_{syn}\)
为了更好对齐数据集,会使用上一轮计算的BN中的mean和variance 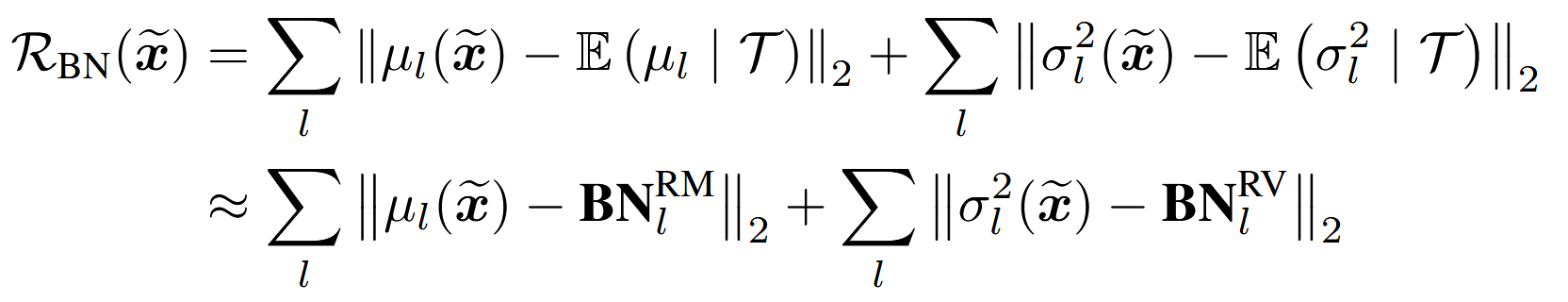
此外,作者每次是随机在合成数据上截取一个固定大小的区域进行参数优化,从而防止过拟合。
最后一步,对合成数据集重新进行label标注,这一步使用\(\theta_{T}\)即可 \[ \tilde{y} = \Phi_{\theta_{T}}(\tilde{X}_{R})\tag{3} \] 那么之后就可以用其它数据集在\(C_{syn}\)上进行训练了 \[ L_{syn} = -\sum_{i} \tilde{y}_{i}\log \Phi_{\theta_{C_{syn}}}(\tilde{X}_{R_{i}})\tag{4} \]
总体来说,通过先固定原始数据集\(C_{pre}\)的信息,让\(C_{syn}\)来匹配这一信息,可以将原本耦合的两层优化解耦,实现线性复杂度。相比之下,原本是先让模型学习\(C_{syn}\)上的信息,再用\(C_{pre}\)来评判模型,就会繁琐很多。