VAE学习笔记
VAE学习笔记
在生成模型中,如果我们有一组数据\(X_1,X_2,...X_n\),那么最理想的情况就是能够建模出\(X\)对应的实际分布\(p(X)\)。那么之后要生成新的\(X\)的话,只要选择\(p(X)\)中对应概率密度比较大的\(X\),它就大概率是合理的样子 但是只有分布的采样而且不清楚其具体的分布形式的话,我们无法构造概率密度,也就无法使用正常方法来建模。但是考虑到auto-encoder架构的话,我们可以利用encoder之后得到的隐向量\(Z\)来对\(X\)进行建模,具体来说 \[ q(X) = \sum_{Z}q(X|Z)q(Z) = \sum_{Z}q(X,Z) \] 这里的\(q(Z)\)是先验分布,我们的目标就是希望\(q(X)\)能够逼近\(p(X)\),这样,我们既有了数据的实际分布,又可以通过采样\(Z\)来进行生成工作。 不妨设\(p(X,Z) = p(Z|X)p(X)\),那么显然\(p(X)\)也可以通过全概率公式转化为上述式子的模样。如果我们希望\(q(X)\)逼近\(p(X)\),此时一个很好的方法就是让\(q(X,Z)\)逼近\(p(X,Z)\)。我不太确定这两者的效果是不是完全一样的,但在auto-encoder的背景下,利用好隐藏变量\(Z\)显然是一个不赖的主意。 那么衡量两个分布的距离,不妨用KL散度 \[ \begin{flalign} KL(p(X,Z)||q(X,Z)) &= \int \int p(X,Z )\ln \frac{p(X,Z)}{q(X,Z)}dZdX\\ &= \int p(X) [\int p(Z|X)\ln \frac{p(X,Z)}{q(X,Z)}dZ]dX\\ &=E_{X\sim p(X)}[\int p(Z|X)\ln \frac{p(X,Z)}{q(X,Z)}dZ]\\ &= E_{X\sim p(X)} [\int p(Z|X)(\ln p(X) + \ln \frac{p(Z|X)}{q(X,Z)})dZ]\\ \end{flalign} \] 对于式子中的前者,有 \[ {\begin{flalign} E_{X\sim p(X)} [\int p(Z|X)\ln p(X)dZ] &= E_{X\sim p(X)} [ \ln p(X)] \end{flalign}} \] 其中\(p(X)\)是关于\(X\)的先验,它应当是一个常数,从而这整一项是一个常数C,从而 \[ \begin{flalign} KL(p(X,Z)||q(X,Z)) &= E_{X\sim p(X)} \left[ \int p(Z|X)\ln \frac{p(Z|X)}{q(X,Z)}dZ \right] +C \end{flalign} \] 从而可以设计出Loss为 \[ \begin{flalign} Loss &= E_{X\sim p(X)} \left[ \int p(Z|X)\ln \frac{p(Z|X)}{q(X,Z)})dZ \right]\\ &= E_{X\sim p(X)} \left[ \int p(Z|X)\ln \frac{p(Z|X)}{q(Z)q(X|Z)})dZ \right]\\ &= E_{X\sim p(X)} \left[- \int p(Z|X)\ln q(X|Z)dZ + \int p(Z|X) \ln \frac{p(Z|X)}{q(Z)})dZ \right]\\ &= E_{X\sim p(X)} \Big[E_{Z\sim p(Z|X)}[-\ln q(X|Z)] + KL(p(Z|X)||q(Z)) \Big]\\ \end{flalign} \] 让我们来仔细观察这个设计出来的Loss。首先\(X\sim p(X)\)表示输入样本\(X\)来自于一个已经存在的分布\(p(X)\),当然这个分布具体是什么样子我们并不知道,逼近该分布也正是我们的目标。 对于\(E_{Z\sim p(Z|X)}[-\ln q(X|Z)]\)这一项,\(Z\sim p(Z|X)\)表示该隐变量\(Z\)的分布来自于某个样本\(X\),在auto-encoder中实际就是\(X\)输入之后经过encoder得到\(Z\),这也是非常的合理,而整体来看这一项也就是一般auto-encoder的目标:通过隐变量\(Z\)重建\(X\)得到熵。所以这一项实际上就是希望重建之后与原样本的差距能够尽可能的小。 对于后一项\(KL(p(Z|X)||q(Z)\),它是希望隐变量\(Z\)关于\(X\)的后验与其先验尽可能的接近。对于这一点我是这样理解的:首先隐变量\(Z\)服从一个分布\(q(Z)\),这是一个与\(X\)无关的分布。而我们实际做decoder的时候,肯定是从encoder之后的分布中去采样\(Z\)的,也就是说,对于给定样本\(X\),我们是从分布\(p(Z|X)\)中去采样的。分布\(p(Z|X)\)中含有\(X\)的信息,因此其decoder的结果在Loss前一项的约束下一定会往靠近\(X\)的方向走,这回导致模型生成能力被削弱。而正是因为\(KL(p(Z|X)||q(Z)\)的约束,\(p(Z|X)\)也会受到分布\(q(Z)\)的影响,而这是一个与\(X\)无关的分布,那么感性理解,模型自然会拥有更强大的生成能力。
到这里我们也不难看出,Loss中的两项其实是相互拮抗的,这有点类似于GAN。但是不同的是,这里对抗的两项都是在不断演化中,而在GAN中鉴别者往往是不动的,只有造假者在不断进化。因此在考虑这个Loss的时候,也不能指望两个分项能够同时下降:它们一个控制生成的精确程度,另一个控制生成的多样程度(用词匮乏,意会即可...)所以我在想也可以通过在它们之间添加超参的方式来人为控制趋势。
接下来尝试给出一些合理的设定,从而完成整个Loss的设置 目前我们的Loss是 \[ \begin{flalign} Loss &= E_{X\sim p(X)} \Big[E_{Z\sim p(Z|X)}[-\ln q(X|Z)] + KL(p(Z|X)||q(Z)) \Big]\\ \end{flalign} \] 在这里,\(p(X)\)是一个已经存在的分布,我们需要对其进行近似,所以这里不必对其进行建模。而之后的\(p(Z|X),q(X|Z),q(Z)\)我们都不知道,需要将其显式表示。
首先看\(q(Z)\),根据之前所描述,它是一个与样本\(X\)无关的分布,并且起到了牵制模型生成能力的作用,从而我们可以对其进行合理的假设,比如Gaussian分布,简单点的话就是\(N(0,I)\),也就是标准的多元gaussian分布 接下来,\(p(Z|X)\)表示encoder之后隐变量的分布,\(q(X|Z)\)表示decoder之后生成结果的分布。接下来我们会假设这两个分布的具体形式,同时用模型来学习它们的参数(如果不用模型学习参数的话那这整个loss设计出来也没啥意义了,至于为啥两个分布都要通过模型来训练,而不是由\(q(Z)\)和其中一个分布来尝试得到另外一个分布,这一点我后面再思考一下)
由于\(p(Z|X)\)需要往\(q(Z) =
N(0,I)\)靠近,为了方便计算不妨假设其也是各分量独立的gaussian分布,那么对于每一个分量来说,都有
\[
p(Z|X)^{(k)} = N(u_{k},\sigma_{k}^2)
\] 从而对于\(KL(p(Z|X)||q(Z))\),其每一个分量的结果为
\[
\begin{flalign}
KL(N(\mu,\sigma^2)||N(0,1)) &= \int \frac{1}{\sqrt{2\pi
\sigma^2}}e^{-(x-\mu)^2/2\sigma^{2}}\left(
\log\frac{e^{-(x-\mu)^2/2\sigma^{2}}/\sqrt{2\pi
\sigma^2}}{e^{-(x)^2/2}/\sqrt{2\pi}} \right)dx\\
&= \int \frac{1}{\sqrt{2\pi
\sigma^2}}e^{-(x-\mu)^2/2\sigma^{2}}\log\left\{ \frac{1}{\sqrt{ \sigma^2
}}e^{-(x-\mu)^2/2\sigma^{2}+x^2/2} \right\}dx\\
&= \frac{1}{2}\int \frac{1}{\sqrt{2\pi
\sigma^2}}e^{-(x-\mu)^2/2\sigma^{2}}\left[ -\log \sigma^2 + \left(
x^2-\frac{(x-\mu)^2}{\sigma^2} \right) \right]dx\\
&=\frac{1}{2}\int \frac{1}{\sqrt{2\pi
\sigma^2}}e^{-(x-\mu)^2/2\sigma^{2}}(-\log \sigma^2)dx + \frac{1}{2}\int
\frac{1}{\sqrt{2\pi \sigma^2}}e^{-(x-\mu)^2/2\sigma^{2}}\left(
x^2-\frac{(x-\mu)^2}{\sigma^2} \right)dx
\end{flalign}
\] 对于第一项,将\(-\log(\sigma^2)\)提出来之后,里面就是一个完整的gaussian分布的积分,从而结果为\(-\frac{1}{2}\log(\sigma^2)\)
之后一项套用方差与二阶矩的定义之后得到结果为\(\frac{1}{2}(\mu^2 + \sigma^2 -1)\)
从而得到每一个分量的结果为 \[
KL(N(\mu,\sigma^2)||N(0,1)) =\frac{1}{2}(-\log\sigma^2 + \mu^2 +
\sigma^2 -1)
\]
那么整体考虑的话,最终得到 \[ KL(p(Z|X)||q(Z)) = \frac{1}{2}\sum_{k=1}^{d}(-\log \sigma_{k}^2+ \mu_{k}^2 + \sigma_{k}^2-1) \] 其中\(d\)是隐变量的维度,这里的\(\sigma_{i},\mu_{i}\)就作为可训练的参数来进行计算了,然后通过反向传播来实现优化。
最后我们来处理\(q(X|Z)\),这个分布只是在最后计算熵用的,作者在文中提供了两种选择:Bernoulli分布与gaussian分布。在各分量独立的假设下,具体到每一个分量的话,其实就是01分布与单变量的gaussian分布。这里简单讨论以下后者。
还是记其是一个各分量相互独立的gaussian分布,将其分布显式地写出来,为
\[
q(X|Z) = \frac{1}{\prod_{k=1}^{D}\sqrt{
2\tilde{\sigma}_{k}^2(Z)}}\exp\{-\frac{1}{2}\| \frac{x -
\tilde{\mu}(Z)}{\tilde{\sigma^2(Z)}} \|^2\}
\] 其中\(D\)表示最终输出结果的维度
这里为了与之前做区分,将方差与均值记为\(\tilde{\sigma}(Z),\tilde{\mu}(Z)\),同时因为这是一个与\(Z\)有关的分布,所以加了\((Z)\)的后缀 那么不难得到 \[
-\ln q(X|Z) = -\frac{1}{2}\| \frac{x -
\tilde{\mu}(Z)}{\tilde{\sigma^2(Z)}} \|^2\ +
\frac{1}{2}\sum_{k=1}^{D}\tilde{\sigma}_{k}^2(Z) + \frac{D}{2}\ln 2\pi
\] 不过这里往往会把\(\sigma_{k}\)固定为相同的值,从而得到
\[
-\ln q(X|Z) \sim -\frac{1}{2\sigma^2}\| x - \tilde{\mu}(Z)\|^2\
\] 而这实际上是一个MSE
最终我们也就完成了Loss的设计,这中间模型的架构也就逐渐清晰了
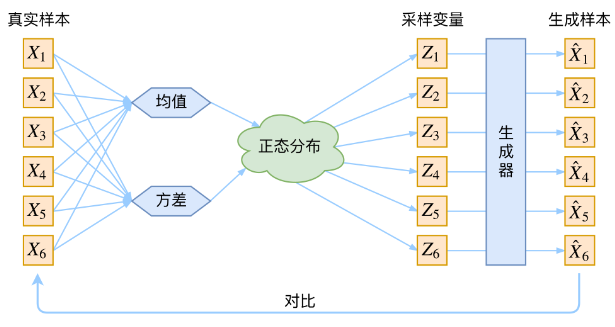
最后在训练阶段还有一个问题没有解决,那就是decoder阶段对隐变量\(Z\sim p(Z|X)\)进行了采样操作,所以需要重参数技巧进行处理来保证反向传播的可行性。这一点我也专门写过一篇文章,自认为还是比较详细的。而这里\(Z\sim p(Z|X)\)假设为是一个gaussian分布,那么实际处理起来也很简单,这里不再赘述。
最后,我们注意到,从隐变量\(Z\)的分布,到encoder,decoder阶段的后验\(p(Z|X)\)以及似然\(q(X|Z)\)都被假设为gaussian分布。由于\(q(X|Z)\)最终是会逼近\(p(X|Z)\),我们不妨以后者代替之,然后看看三者都假设为gaussian分布的合理性。
可以这样来考虑: > \(p(X)\)是任意一个分布,\(p(Z) \sim N(0,I)\)的情况下,能否得到合理的\(p(X,Z)\),使得\(p(X|Z),p(Z|X)\)都是gaussian分布
在\(p(X)\)满足gaussian分布时,该问题存在一个解。 但是当\(p(X)\)不满足gaussion分布的时候,以上命题应该是不成立的。这一点我之后应该会补充。
总之,我们发现,VAE的假设的合理性其实是依靠输入数据\(p(X)\)的分布类型的,这并不是非常合理,应该也是其生成图像较模糊的原因。以一个gaussion分布来近似一个未知分布,就像以椭圆去拟合矩形,椭圆再怎么样也只有两个参数,拟合能力终究有限。