Instruction tuning with loss over instructions
提出在对llm做fine tuning的时候,指令部分也加入loss计算。给定指令序列\(I\)以及对应的Response序列\(C\),原本的训练目标可以表示为 \[ P(C|I) = \sum_{t=1}^{|C|}P(c_{t}|I,c_{<t}) \] 考虑到指令序列之后,训练目标可以表示为 \[ P(C,I) =\sum_{t=1}^{|C|+|I|} P(x_{t}|x_{<t}) \] 这样做的动机是,作者认为,当训练数据中指令序列很长而response很短的时候,只对齐response,可能会导致过拟合,而当训练数据很少的时候,这一点可能会更加严重。此时加入对指令序列的对齐,可以充当一个正则化的作用。
这一结论与[1]刚好可以互补。[1]指出的是,在推理场景下,即response序列很长很长的时候,是否对齐prompt没啥影响,而本文这种\(\frac{len(I)}{len(C)}\)较大的情况下,对齐指令就会很有用了。
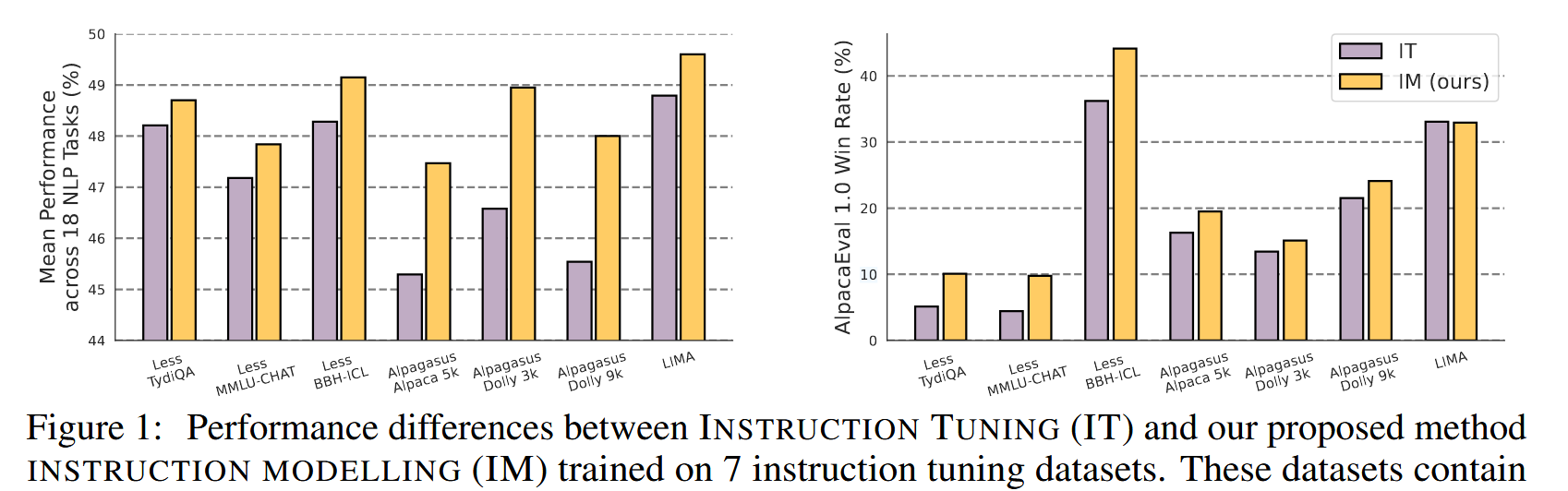
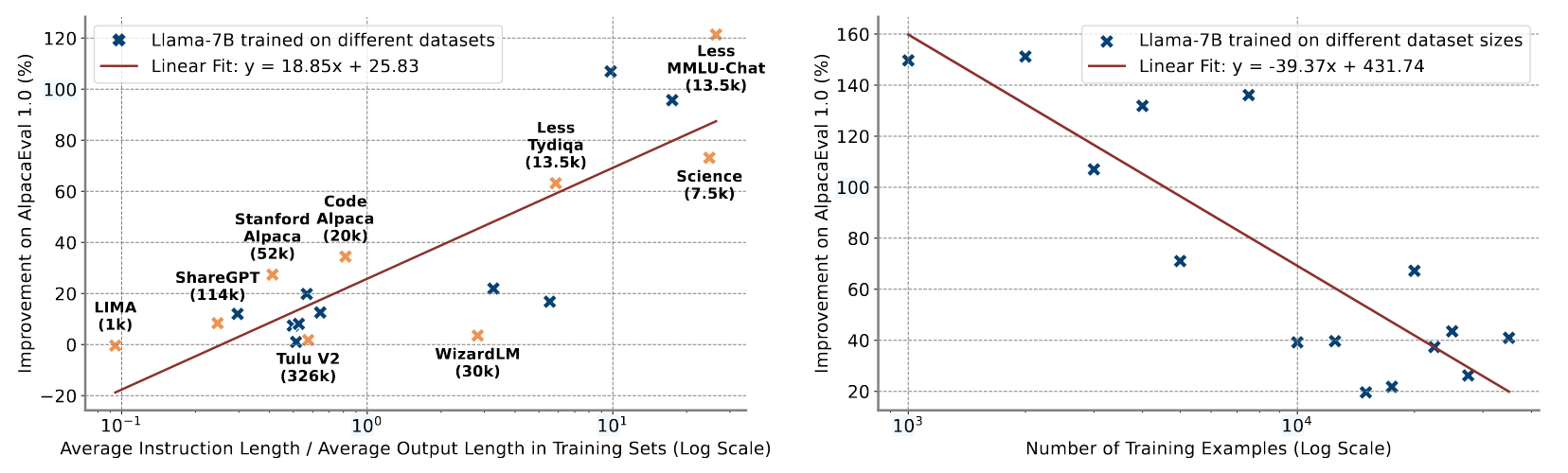
上图中IT代表正常的Instrucion-Tuning,IM是加入与\(I\)对齐的IT。 从实验结果来看确实如此。不过作者也强调了,这种方法并非对所有数据集都有用,它更适合在数据量小,\(\frac{len(I)}{len(C)}\) 较大这种更容易导致过拟合的场景下使用,上述数据集的\(\frac{len(I)}{len(C)}\)基本都在\(>1\)的范围。
同时作者也验证了一下对齐\(I\)起到了正则化防止过拟合这一说法的合理性。
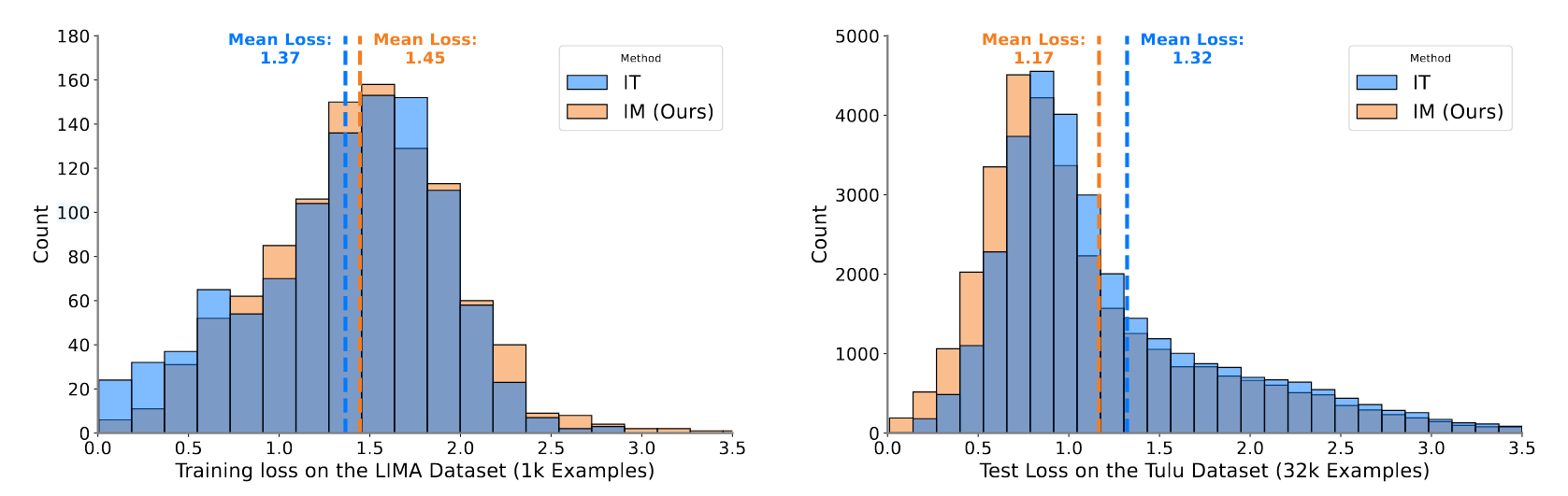
这里左侧的LIMA数据集用于训练,右侧的Tulu数据集用于测试。可以看到与指令序列对齐之后,在训练集上的Loss相对变大,但是测试集上的Loss变小了。这里测试时只考虑response上的生成质量。
Conclusion
总体来说,在处理指令详细,但是输出简洁的数据集,或者资源受限,数据集规模较小的时候,对指令部分也加入对齐,可以有效抑制模型过拟合,取得相对更好的效果。
Reference
[1] Chen, W., Kothapalli, V., Fatahibaarzi, A., Sang, H., Tang, S., Song, Q., Wang, Z., & Abdul-Mageed, M. (2025). Distilling the Essence: Efficient Reasoning Distillation via Sequence Truncation.