FROM CORRECTION TO MASTERY: REINFORCED DISTILLATION OF LARGE LANGUAGE MODEL AGENTS
对agent
distillation的优化。以往KD范式普遍是对一条策略直接进行对齐,其中数据来自TGO或者是SGO。之前的工作已经证明SGO对于缓解学生的exposure
bias存在帮助,但是SGO本身往往也面临着exposure bias的影响。 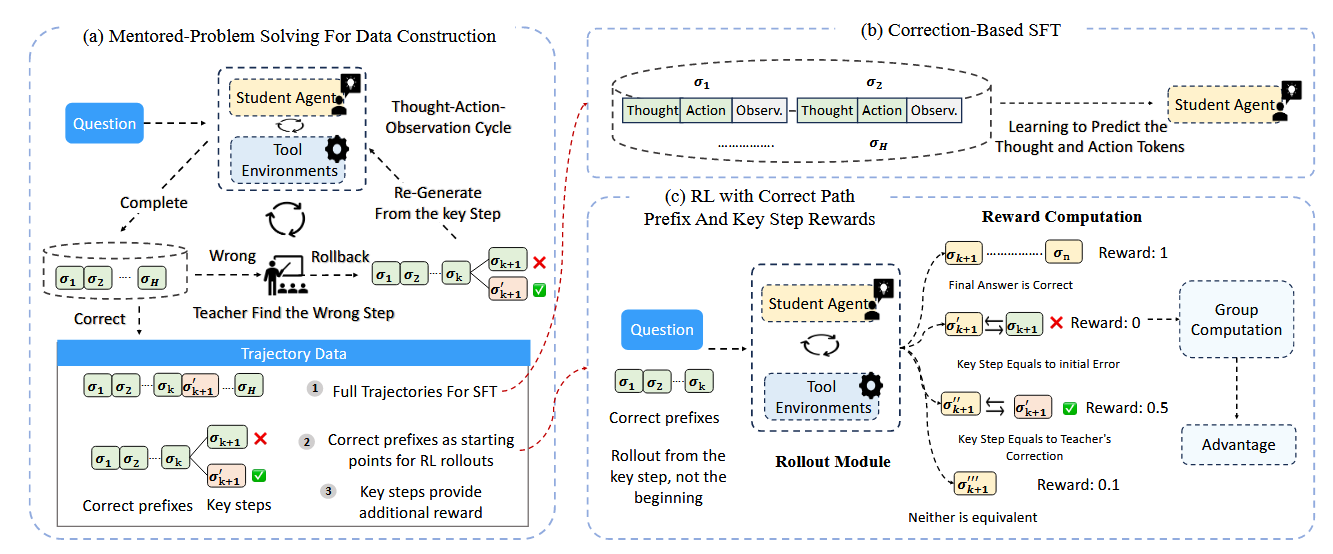
Trajectory Generation

这里证明,当不存在其它干预的时候,学生生成策略会随着策略长度而存在平方级别的误差。因此尝试在学生生成SGO的时候引入教师进行干预:当学生生成第一个错误action \(a_{k}\)的时候,教师才进行介入并且将其改为正确结果\(a_{k}'\),然后学生在\(a_{k}'\)的基础上重新生成下一个action,从而得到action序列为 \(a_{1},a_{2},\dots a_{k-1},a_{k}',a_{k+1},\dots\)
由此得到的教师介入过的SGO‘,其误差相对于策略长度,可以控制在线性范围内

SFT Based On SGO'
接下来就是利用生成好的数据对学生进行Behavior
Cloning对齐。对于每一条策略,以往的方法往往是对齐最后一个action,但是此时每一条策略中往往会存在多个教师介入过的,学生生成效果差的action,在这些地方进行对齐往往能有更好的效果。与此同时,一条策略也可以进行多次对齐,数据效率更高。

RL Phase
使用GRPO进行RL训练。RL面临的常见问题:稀疏奖励,以及长轨迹导致的梯度估计方差过大
与SFT环节类似,在不同的教师纠正过的地方添加reward并进行对齐,这就同时解决了上述两个问题。对于reward的具体设置:如果最终结果正确的话,会有一个更大的reward
\(R_{final}\)。同时在中间部分为了区分不同token的效果,reward设置为
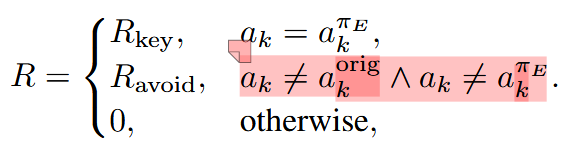 其中\(a_{k}^{\pi_{E}}\)是教师纠正结果,\(a_{k}^{orig}\)是学生原始action。如果学生学到了教师的正确action,会有更大的reward,如果其避免了原本的错误,但是依然没有达到教师的结果,会有一个较小的reward。
其中\(a_{k}^{\pi_{E}}\)是教师纠正结果,\(a_{k}^{orig}\)是学生原始action。如果学生学到了教师的正确action,会有更大的reward,如果其避免了原本的错误,但是依然没有达到教师的结果,会有一个较小的reward。
This reward scheme provides informative credit assignment at the student’s weakest step, while maintaining prioritization of final task success
Conclusion
精华在于引入教师的纠正,但同时又保留了大部分学生的推理结果,让生成的SGO匹配学生当前性能,又不会具有过大的误差。
以及,学生是被允许自由探索,与环境交互的,这可能可以带来新路线,这也是为什么\(reward_{final}\)会有最大的值。而自由探索,在原始蒸馏中应当是没有的,因此由其得到的模型也没有向上扩展的空间