Merge-of-Thought Distillation
主要是对LLM COT KD中教师监督范式的改进,尝试将复杂推理能力从多个大模型教师转移到一个更加紧凑的学生模型,在数学题目等数据集上有更好表现。目前可以将教师监督分为:单教师监督(STD, Single-Teacher Distillation),多教师监督(MTD, Multi-Teacher Distillation)。前者很好理解,假定了存在一个足够强大的教师模型,对于不同数据集,不同学生,都能给出足够好的指导。但是现有的结论是
different students have different “best teachers,” and even for the same student the best teacher can vary across datasets
既然不存在永远最好的教师,而每次重新选择一个好的教师成本又会很大,那么multi-teacher KD可能会是一个解决方案。COT蒸馏的时候,对于multi-teacher的利用,可以直接将所有teacher的COT直接聚集起来,然后打乱,一起扔给student学习。 这样做的好处是,可以聚集不同教师的能力,期望能让学生从各个方面得到强化。但是COT本身,随着长度的增加,会包含累积的噪声,以及教师能力本身也对COT质量有影响,从而直接引入多个教师的COT,也可能会带来许多噪声。
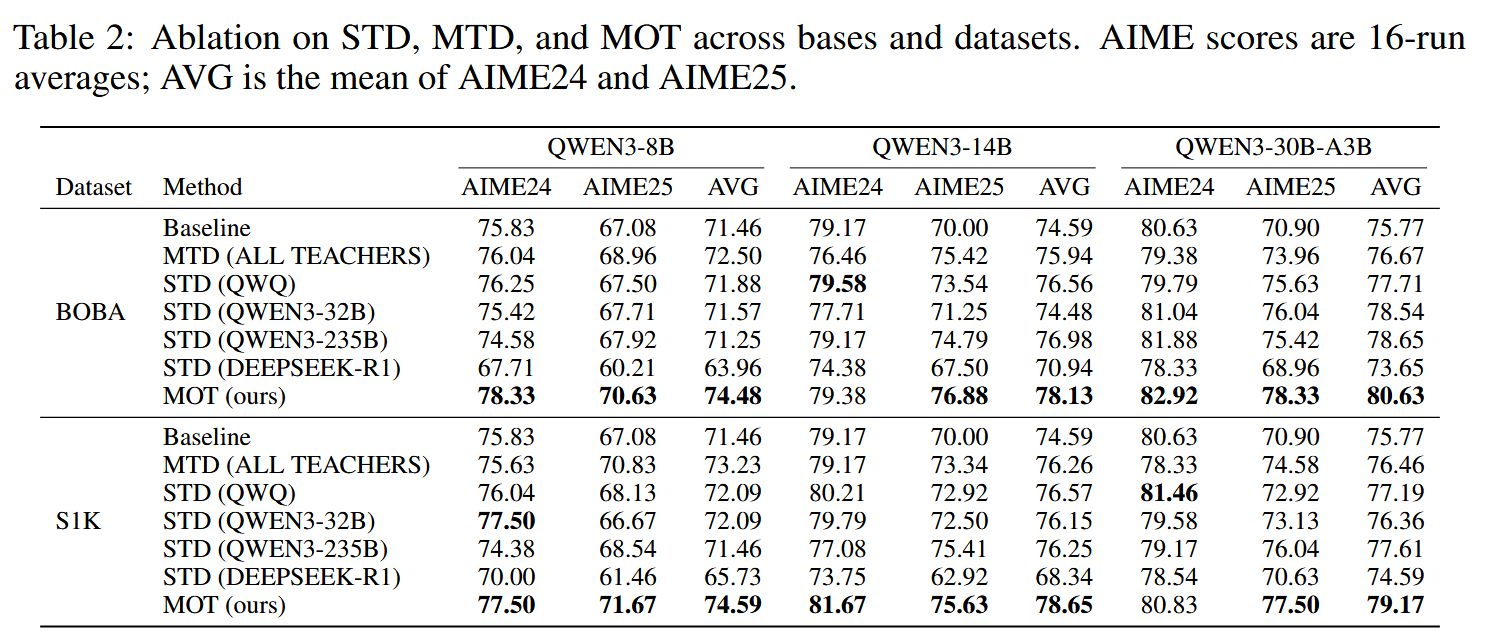 在两个数学数据集上,当学生模型规模比较小(8B)的时候,MTD相比不同single
teacher的STD结果,会有一定优势。但是当模型规模上去(30B)的时候,MTD的结果不优于任何一个single
teacher的STD结果。作者对此的解释是
在两个数学数据集上,当学生模型规模比较小(8B)的时候,MTD相比不同single
teacher的STD结果,会有一定优势。但是当模型规模上去(30B)的时候,MTD的结果不优于任何一个single
teacher的STD结果。作者对此的解释是
as the scales of the student model and the teacher model become increasingly close, the student model is more susceptible to the influence of teachers with closer distributions, thereby collaspe MTD into Best STD
即,当学生规模上去时,其更可能受一个教师的影响,从而MTD退化为STD,此时其它教师的COT的噪声可能就会被放大,从而导致MTD不如STD。 这种操作在scale之后失效,归根结底是不同教师信息之间没有经过协调。因此作者提出MOT。
- 首先,对于不同的教师\(t_{k}\),单独用其COT微调一个学生模型的副本\(s_{k}\),这一步的操作其实与STD训练是一样的
- 从而得到\(k\)个学生模型的副本\(s_{1},s_{2},\dots s_{k}\),将它们的参数直接取平均 \(\theta^{t} = \frac{1}{k}\sum_{i=1}^{k} \theta^{t,k}\)
- 得到\(\theta^t\)之后,重复上述两个步骤,进而得到\(\theta^{t+1},\dots, \theta^T\)
期望通过多轮迭代,让不同教师之间的信息收敛,缓解MTD中不同信息互相冲突的情况。回到图1,也不难看出,MOT在绝大部分数据集,模型规模上都取得了领先。
Conclusion
单个教师可能在某些时候确实是不够的。SGO监督的时候,教师对SGO可能也并不能有很好的认知,此时聚集多个教师的信息可能会有一定帮助。
另外,一个经验性的结论:
相比于直接要求基础模型学习各个方面的能力(通过multi-loss或者multi-teacher),可能更应该对其在各个方面单独训练,然后再尝试合在一起。