前言:
对这玩意只能说是能用,只是会套别人的轮子,不过还是感觉很有意思,突然就想记录一下
实验目的:
熟悉ply的基本使用,能够通过编写无二义性的语法以及利用yacc来实现对化学分子式的基本解析
实验内容:
编写程序并且对化学分子式进行解析,得到其内部元素个数
以下是例子:
1 2 3 4 5 6 atom_count("He" ) == 1 "H2" ) == 2 "H2SO4" ) == 7 "CH3COOH" ) == 8 "NaCl" ) == 2 "C60H60" ) == 120
思路:
首先需要进行词法分析的构造
词法分析
在本次实验中我们显然只需要对化学元素以及数字进行解析。事实上在一个化学分子式中确实不会出现除这两者之外的其它事物
对化学元素的解析:在给定的化学元素周期表中,只要给出一个恰好包括所有元素的正则表达式即可
对数字的解析:不难得到
由此我们给出词法分析的代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 'NUMBER' ,'SYMBOL' def t_NUMBER (t ):r'\d+' int (t.value)return tdef t_SYMBOL (t ):r""" C[laroudsemf]?|Os?|N[eaibdpos]?|S[icernbmg]?|P[drmtboau]?| H[eofgas]?|A[lrsgutcm]|B[eraik]?|Dy|E[urs]|F[erm]?|G[aed]| I[nr]?|Kr?|L[iaur]|M[gnodt]|R[buhenaf]|T[icebmalh]| U|V|W|Xe|Yb?|Z[nr] """ return t;' \t' def t_error (t ):print ("Illegal character '%s'" % t.value[0 ])1 )
语法
考虑的基本语法如下:
1 2 3 4 species_list -> species_list species
其中\(species\_lsit\) 表示一个化学分子式,\(species\) 表示一个基本的化学元素的表达式,\(SYMBOL\) 表示能够识别出来的化学元素,\(COUNT\) 就表示对应的次数,一个表达式由上述两者组成
此外,为了让最后的结果能够对不同元素的次数加以区分,我们建立了一个结构体来方便计数
1 2 3 4 5 6 7 class Atom (object ):def __init__ (self, symbol, count ):def __repr__ (self ):return "Atom(%r, %r)" % (self.symbol, self.count)
从而不难得到语法如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 def p_splist_sp (p ):'splist : splist sp' 1 ].append(p[2 ])0 ]=p[1 ]def p_splist_to_sp (p ):'splist : sp' 0 ] = [p[1 ]]def p_sp_symbol (p ):'sp : SYMBOL' 0 ] = Atom(p[1 ],1 )def p_sp_symbol_count (p ):'sp : SYMBOL NUMBER' 0 ] = Atom(p[1 ],p[2 ])def p_error (p ):print ("Syntax error in input!" )
当单独一个\(SYMBOL\) 或者\(SYMBOL\) 与\(COUNT\) 规约为一个\(species\) 时,我们直接将其包装为一个基本结构体。否则用一个以Atom为基本元素的数组来记录其内包含的元素及其个数
yacc采用LALR分析法,当我们编译这个程序的时候,就会在同一个目录下得到LALR生成的分析表parser.out,并且之后会根据其中的DFA来决定分析时的移进/归约操作
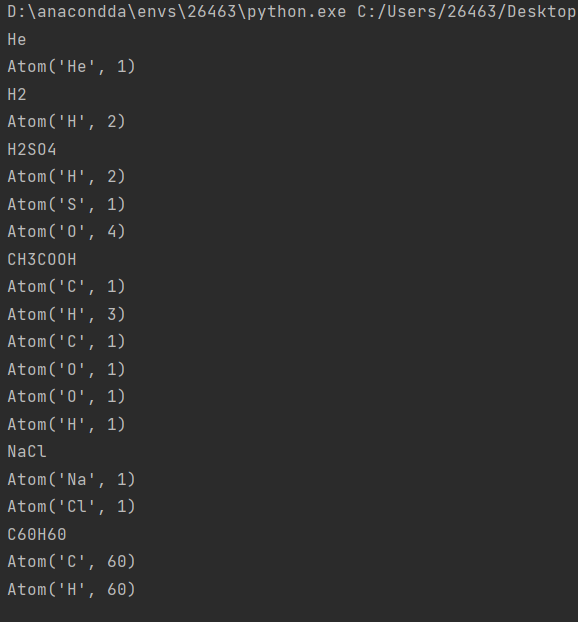
实验结果&改进
image-20231223133245938
不过注意到这个记录方法还是存在一定不足,在\(CH3COOH\) 中\(C\) 出现了两次,但是两次分开记录了,最好可以合并在一起
由此我们可以采用字典来记录
以下是\(chemistry\_caculate.py\) 的改进后的语法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 import ply.yacc as yaccfrom calclex import tokensdef p_splist_sp (p ):'splist : splist sp' for sym,cnt in p[2 ].items():if sym not in p[1 ]:1 ][sym]=cntelse :1 ][sym]+=cnt0 ]=p[1 ]def p_splist_to_sp (p ):'splist : sp' 0 ] = p[1 ]def p_sp_symbol (p ):'sp : SYMBOL' 0 ] = {}0 ][p[1 ]] = 1 def p_sp_symbol_count (p ):'sp : SYMBOL NUMBER' 0 ] = {}0 ][p[1 ]] = p[2 ]def p_error (p ):print ("Syntax error in input!" )
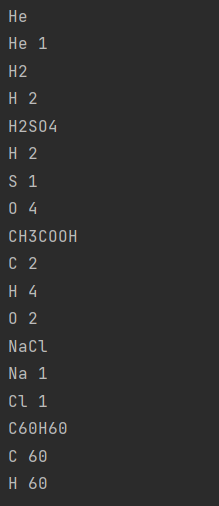
此时结果如下:
image-20231223140716841
可以看到确实已经合并在一起了
更多细节参见文件中的PLY使用手册