Selective Reflection-Tuning: Student-Selected Data Recycling for LLM Instruction-Tuning
微调LLM的时候,数据往往来自提前设定好的数据集,最近有工作会提前用教师模型对数据进行加工,期望这可以让数据更加优质,从而推动学生模型的训练。但是这种操作假设教师的改动总是对学生有益的,这一点也许并不是那么合理。
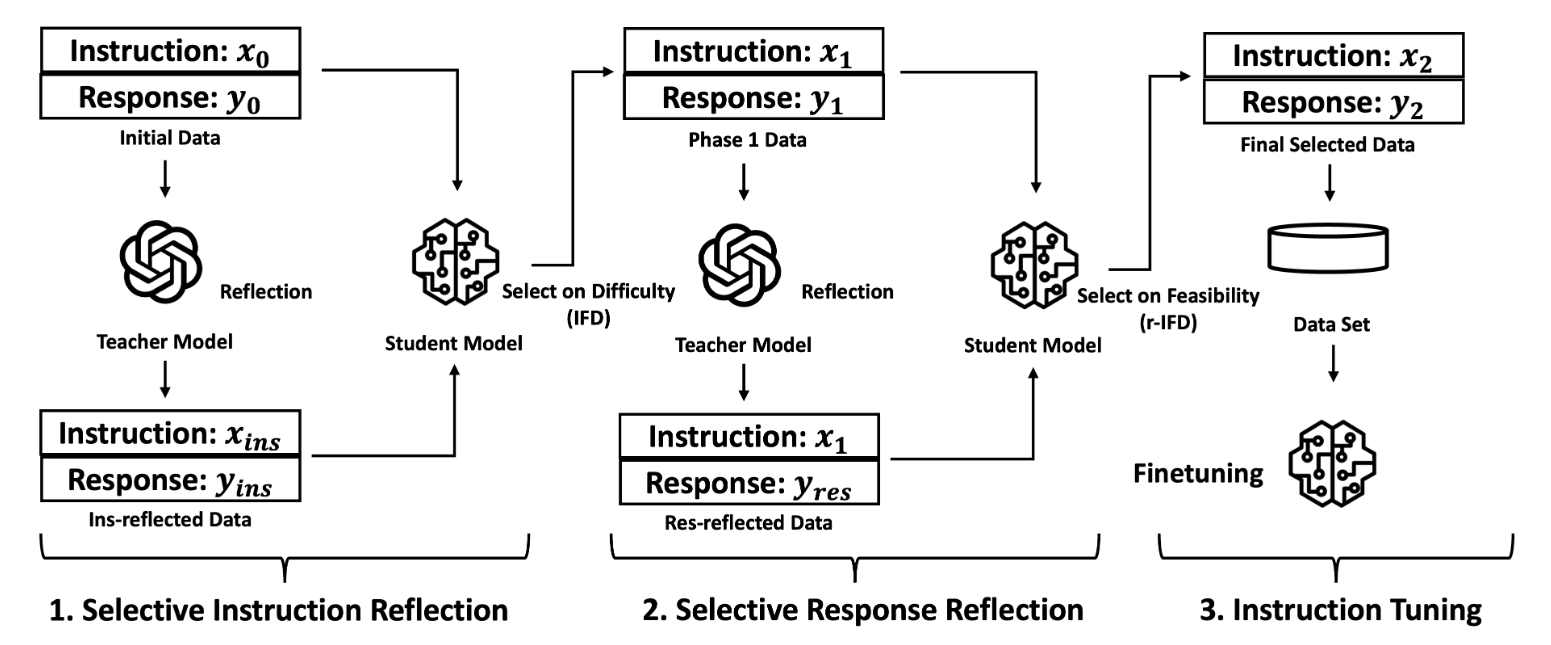
本文尝试引入学生的信息来帮助进行数据增强。原本以教师为中心的反思微调(Reflection-Tuning)方法包含两个步骤:
- 设定了一系列标准来评估原始指令的优劣,包括“主题的复杂度”,“回答该指令所需的知识储备”,“指令的模糊程度”等。教师依据这些标准进行反思,在此基础上生成更好的指令以及对应的回答
- 对于生成的新的指令以及回答,设定了另外的评估回答的一系列标准,包括“回答是否有帮助”,“回答是否准确”等。教师依据此对模型的回答进行评价与反思,在此基础上生成更好的回答。
当然这并没有考虑到学生的适配度,也许教师认为“好”的,对学生并不是。因此针对上述两个步骤分别提出两个指标进行比较:
- 指令遵循难度(IFD)分数:该指标衡量学生模型生成相应响应的指令难度:\[ IFD_{\theta}(y|x) = \frac{ppl(y|x)}{ppl(y)} = \exp(L_{\theta}(y|x) - L_{\theta}(y)) \]IFD分数越高,代表指令越难
- 反向IFD(r-IFD)分数:这个新引入的指标通过量化响应如何帮助预测其对应指令来衡量样本的可行性:\[ r\text{-}IFD(x|y) = \frac{ppl(x|y')}{ppl(x)} = \exp(L_{\theta}(x|y')-L_{\theta}(x)) \]r-IFD 分数越低表明学生可以轻易地从响应中推断出指令,这表示良好的对齐和学习可行性。
在反思微调的第一阶段,面对原始指令对\((x_{0},y_{0})\)以及教师反思优化后的\((x_{ins},y_{ins})\),学生分别计算IFD并选择较高的那个,第二阶段也是同样操作,选择\(r\text{-}IFD\)较高的那个
Selective Reflection-Tuning: Student-Selected Data Recycling for LLM Instruction-Tuning
https://sophilex.github.io/posts/24a4ee0c/