DATASET DISTILLATION VIA KNOWLEDGE DISTILLATION: TOWARDS EFFICIENT SELF-SUPERVISED PRETRAINING OF DEEP NETWORKS
尝试在SSL问题中使用data distillation,以往的方法主要针对SL,并不能直接迁移到SSL问题中。
SSL问题一般需要对data训一个encoder \(f\),其loss定义为 \[ L_{BT} = \sum_{i=1}^{d} (1-F_{ii})^2 + \lambda \sum_{i=1}^{d}\sum_{j \neq i} F_{ij}^2\tag{1} \] 其中 \[ F_{ij} = \mathbb{E}_{x \in B} \mathbb{E}_{x_{1},x_{2}\in A(x)} [f_{i}(x_{1})f_{j}(x_{2})]\tag{2} \] 代表对于batch \(B\)中数据\(x\),其不同视图\(x_{1},x_{2}\)在第\(i,j\)个特征的乘积,\(d\)是embedding size 整个\((1)\)式就代表,希望同一样本的不同视图在相同特征上尽可能一直,在不同特征上尽量不相关 从而,利用encoder \(f\),就可以在dataset \(D\)上,训练一个分类器\(g_{D}(f)\)用于下游任务。
对于dataset distillation,我们需要生成一个比原始dataset\(D_{real}\)小得多的\(D_{syn}\),同时满足在\(D_{syn}\)上训练得到的encoder \(f_{\theta_{syn}}\),与在\(D_{real}\)上得到的\(f_{\theta_{real}}\)应当尽量接近,这可以表述为 \[ D_{syn}^* = argmin_{D_{syn}} \mathbb{E}_{x \sim D_{real}} D(f_{\theta_{syn}}(x), f_{\theta_{real}}(x))\tag{3} \] 其中\(D\)用于衡量两者距离
SL中常用MATCHING TRAINING TRAJECTORIES来进行dataset
distillation,具体来说,就是希望在两个dataset上训练的\(f\),其参数优化轨迹是类似的,loss定义为
\[
L_{DD}(D_{syn}) = \frac{||\hat{\theta}_{t+N} -
\theta^*_{t+M}||^2}{||\theta^*_{t} - \theta^*_{t+M}||^2}\tag{4}
\] 其中\(\theta^*\)是在\(D_{real}\)上训练的参数,\(\hat{\theta}\)是在\(D_{syn}\)上训练的参数,上式分子最小化N步之后与在原本数据集上M步之后的差距,分母消除专家轨迹本身的尺度影响
注意到由不同的数据出发,训练得到的参数优化轨迹是会有一定的偏差的,作者证明在SSL下loss受batch内数据的影响很大,方差很大,而每一个小batch的高方差,会导致参数训练轨迹的累计高方差。轨迹方差大,那么收敛就会慢,从而训练轨迹也会变长,恶性循环。
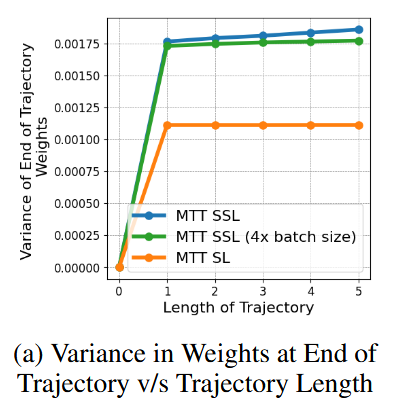
相比之下,SL的方差较小,那么轨迹长度也会小(收敛快),是利于参数优化轨迹的拟合的。因此作者尝试找到一种方式,将原本在SSL任务上训练得到的f,转化为用SL任务训练得到。
作者用KD来非常巧妙地实现了这种转化。具体来说,先在\(D_{real}\)上无监督训练一个teacher encoder \(f_{\theta_{T}}\),然后将SL任务定义为:在dataset上训练一个student \(f'\),其目标就是拟合\(f_{\theta_{T}}\),此时任务有了ground truth,就已经是一个SL任务了,从而实现SSL向SL的转化。 那么按照轨迹匹配的目标,我们先在\(D_{real}\)上训student,\(f_{\theta^*}\),其Loss自然表示为 \[ \mathbb{E}_{x_{i}\in D_{real}}L_{MSE}(f_{\theta^*}(x_{i}), f_{\theta^T}(x_{i}))\tag{5} \] 其参数优化路径就是前文提及的专家轨迹了。之后我们再在初始化好的\(D_{syn}\)上训\(f_{\hat{\theta}}\),其Loss的设计,类似\((5)\),表示为 \[ \mathbb{E}_{x_{i}\in D_{real}}L_{MSE}(f_{\hat{\theta}}(x_{i}), f_{\theta^T}(x_{i}))\tag{6} \] 轨迹匹配时,首先选一个epoch \(t\),并令\(\hat{\theta}_{t} = \theta^*_{t}\),然后从第\(t\)步之后,利用\((5),(6)\),分别对在\(D_{real}\)和\(D_{syn}\)上训练的\(f_{\theta^*},f_{\hat{\theta}}\)进行参数更新,并依据\((4)\)式得到两者轨迹匹配的Loss \(L_{DD}\),最终用\(L_{DD}\)更新\(D_{syn}\)即可。
实际实现的时候还有一些细节,比如\(f_{\theta^*}\)的训练,是同时训了K个,之后轨迹匹配时,随机选一个expert的训练轨迹进行匹配,用以减少随机影响。整体流程如下

总结下来,作者利用KD,巧妙地将对encoder的训练任务范式由SSL转化为SL,从而减轻了轨迹匹配中的方差的影响,进而可以将SL dataset distillation中轨迹匹配方法自然地迁移到SSL中,非常巧妙。